


This article was also published on Medium.
In the previous blog post, we established the foundation of the modern data stack, its key components, and how they are integrated to ensure seamless data movement and management. Now, let’s explore another critical aspect of the modern data stack: data sharing.
A core value proposition of the modern data stack lies in its ability to easily support data sharing needs. It promises to enable seamless collaboration with business partners, finally eliminate persistent data silos within organizations, and streamline complex transitions like M&A that involve diverse infrastructure. Furthermore, the increasing demand for AI and data-driven insights necessitates robust data sharing capabilities across various platforms, clouds, regions, and providers.
To achieve these and other data-sharing outcomes, the modern data stack needs to ensure that data product owners can easily share data both within the corporation and across companies—without giving up control, losing privacy protections, compromising security, or running afoul of regulatory requirements. Historically, this was one of the most challenging requirements on data infrastructure, but fortunately, the modern data stack has great solutions to these challenges.
The App layer: Employ built-in sharing options while limiting DIY costs
The application and solution layer is inherently heterogeneous, and thus so are the sharing options for this layer. They also span the spectrum from “easy buttons” (no-code solutions) to expensive and complex DIY integration projects involving third-party iPaaS platforms or homegrown approaches.
Let’s break down the different ways data can be shared at the app layer, in order of increasing complexity:
- Built-in “SaaS-to-SaaS” data sharing: The easiest solutions are those provided by SaaS services out of the box. For example, HubSpot natively integrates with Salesforce to share customer information without the need to purchase or deploy additional software. Like the SaaS applications being connected, everything is fully managed and, post configuration, the solution “just works”.
- EiPaaS: Legacy enterprise integration Platform-as-a-Service offerings, such as Mulesoft and Boomi, along with more modern options such as Workato, were devised to help solve the problem of integrating SaaS solutions (and in some cases, in-house applications as well). These platforms offer fully managed implementations that abstract away the underlying compute and storage infrastructure, but still require the integration owner to manage and monitor the data integration.
- “DIY” solutions: For in-house applications and custom cross-company data sharing needs at this layer, APIs and bespoke R&D work are required, along with operational staffing and monitoring in perpetuity.
The Data Lake layer: Leverage native sharing features when possible
Moving below the app layer, we arrive at the data lake layer. This layer has become a central hub for data sharing within and across organizations.
The middle layer of the stack—the data lake—has seen rapid growth and innovation over the last decade. It’s also emerged as a nexus for homogeneous data sharing needs: Internal sharing across departments and external data sharing where both parties already share a common data infrastructure stack, meaning they’ve selected the same data lake vendor.
Originally popularized by Snowflake, “zero copy” sharing of data sets at the data lake layer is a powerful mechanism. Snowflake reduced the formerly complex challenge of cross- and inter-organization data set sharing to a “one click” operation that could be performed by anyone, not just a seasoned data operator, and that worked without the need for ongoing ETL, data operator staffing, continuous monitoring, or other historically necessary overhead.
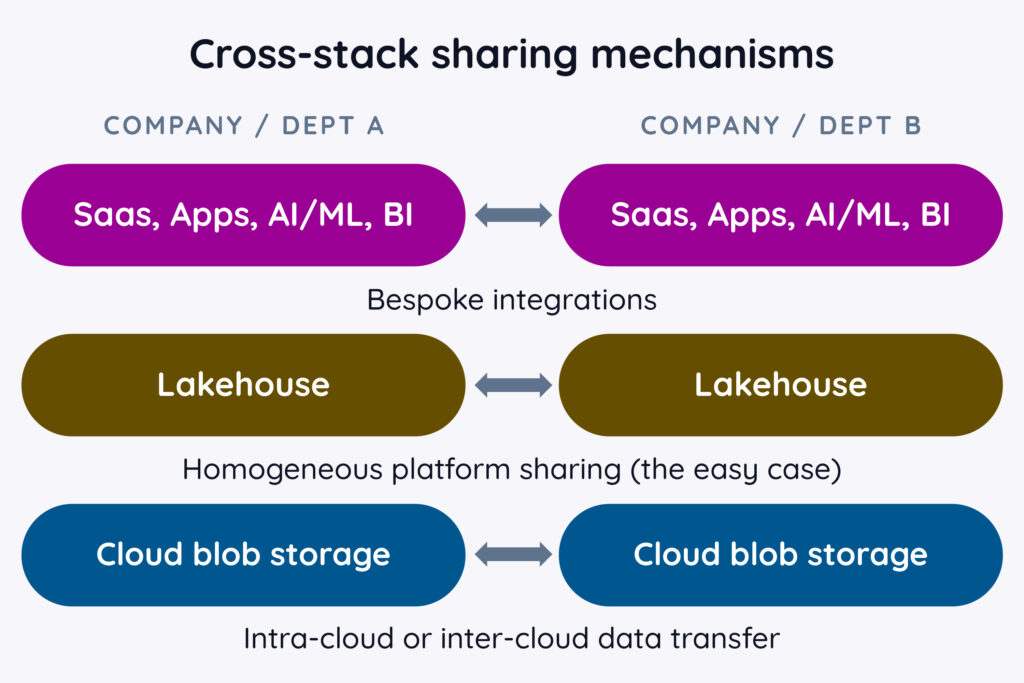
The Storage Layer: The 'Universal Translator' of data
While application and data lake layers offer some data sharing capabilities, the real challenge arises when organizations need to share data across fundamentally different infrastructure environments. This is where the storage layer emerges as the crucial ‘Universal Translator’ for data.
In earlier installments, we discussed how Iceberg, as a common data format and toolset, made it possible to move what used to be proprietary data storage out from inside data lakes and into public cloud object stores. This same observation means that Iceberg data can also take advantage of sharing solutions offered by public cloud providers, as we’ll explore next.
Unlocking heterogeneous sharing
While optimizing for sharing within similar systems is valuable, the reality is that many companies operate with diverse infrastructure due to acquisitions, evolving strategies, or the need to collaborate with external partners who have made different technology choices. In these scenarios, relying on a single vendor’s sharing features – at any of the three layers of the data stack – can fall short. Instead, a solution is needed that embraces heterogeneity, and the storage layer, powered by open standards like Iceberg, provides this foundation.
In these cases, it’s not possible to defer to a singular vendor to solve all the data sharing needs. Instead, the various departments or companies need a solution that embraces the inherent heterogeneity of their technology and infrastructure choices. That’s where the storage layer comes into play.
With respect to sharing, the storage layer has several defining characteristics:
- Ease of migration: The storage isn’t “locked” into a specific vendor; it can be moved, with ease, across clouds, regions, and on- or off-prem.
- Standard representation: Data sets are stored in a common language (Iceberg) that all systems, clouds, companies, data lakes, and tools can understand and manipulate with ease.
- Zero copy reads: Data lakes and other systems can read from the storage tier without needing to “copy the data first” into themselves. (However, data may have to be copied when it needs to be shared in other ways, such as across different public cloud vendors or different geographic regions.)
- Low(er) cost data transfers: Historically, data transfers out of public cloud providers have been set to punitive levels to try to avoid those providers losing business. This practice is increasingly coming under customer and regulator pressure, and public cloud providers are likely to be forced to reduce these punitive pricing practices over time.
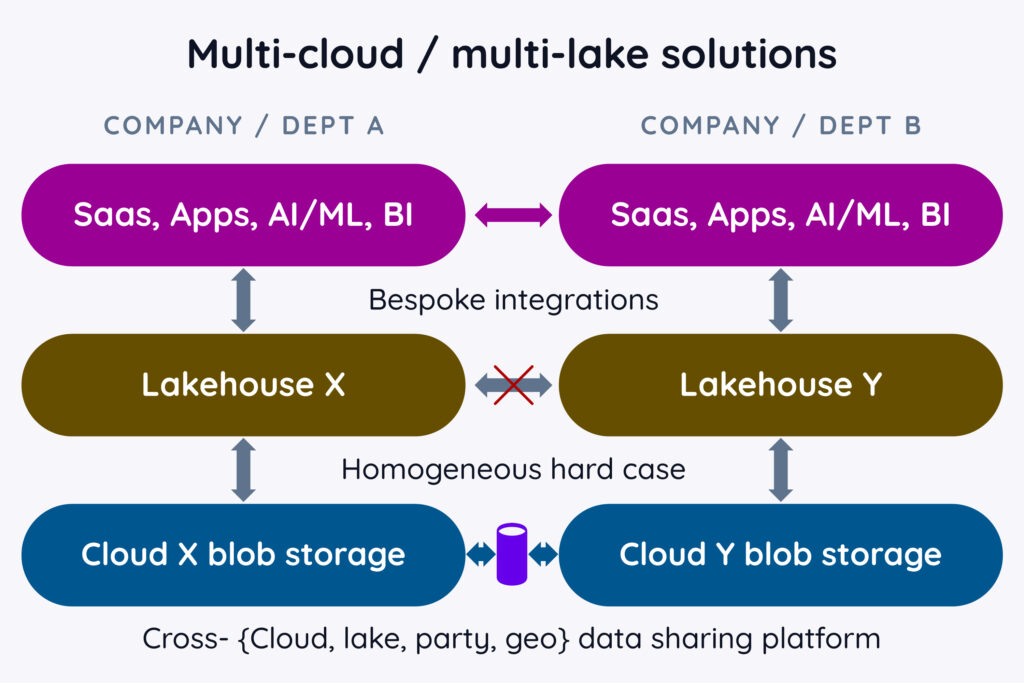
While the storage tier can be used to facilitate heterogeneous sharing (i.e., sharing data across companies, clouds, lakes, regions, or other “data canyons”), solutions to do that are not always easy to implement or deploy, especially when the data being shared has compliance, security, and trust considerations. Addressing these concerns requires going beyond basic data sharing and copying at the storage tier.
Vendia IceBlock: Enabling secure cross-system analytical data sharing
Sharing data across heterogeneous environments—whether between departments, companies, or clouds—requires more than a standard format like Iceberg. It demands a solution that ensures trust, security, and compliance while simplifying the process.
This is where Vendia IceBlock comes in.
IceBlock is a revolutionary approach to data sharing that combines the power of Iceberg with a distributed ledger for immutable metadata tracking. By combining Iceberg’s interoperability with a distributed ledger for immutable data and metadata tracking, IceBlock enables organizations to share data seamlessly and safely across clouds, regions, and systems—unlocking true data democratization.
Key capabilities of IceBlock include:
- Immutable metadata tracking: IceBlock uses a distributed ledger to record who shared what data with whom, ensuring transparency and auditability. This information can be easily exposed through, and integrated with, Polaris or other standard catalog approaches to add to their existing governance and control capabilities.
- Merkle Trees for data integrity: By leveraging Merkle Trees, IceBlock ensures that even large datasets composed of thousands of files remain consistent and traceable without adding appreciable overhead to the time or space required for either batch or incremental updates to tables.
- Privacy and compliance: IceBlock enables fine-grained access controls, ensuring that sensitive data (e.g., PII, PHI) is shared only with authorized parties. It also provides lineage tracking for regulatory compliance.
- Real-time synchronization: IceBlock supports real-time data sharing across clouds, regions, and systems, enabling use cases like data monetization, clean rooms, and partner data-sharing networks that rely on sharing and analyzing data and data updates in real time.
Ultimately, Vendia IceBlock is more than a technical solution—it’s a paradigm shift in how organizations approach analytical data sharing across heterogeneous environments. Here’s how it enables secure and efficient cross-system data exchange:
- Breaking down silos: By enabling seamless data sharing across heterogeneous environments, IceBlock eliminates the need for all parties to adopt the same cloud or data lake solution. This fosters collaboration specifically between differing analytical platforms, breaking down silos and resulting in richer analytical data ecosystems.
- Protecting legacy investments: IceBlock complements existing infrastructure, including on-prem systems, by adding modern data-sharing capabilities. This protects legacy investments while extending their value.
- Enabling data monetization: With IceBlock, organizations can easily monetize their data by sharing it with partners or customers in a secure, compliant manner. Real-time clean rooms and bespoke data products become feasible, opening new revenue streams, without limiting where or to whom data can be distributed.
- Ensuring trust and compliance: IceBlock’s distributed ledger and lineage tracking provide auditable insights into data provenance, access, and usage. This ensures compliance with data privacy regulations like GDPR and CCPA, building trust with partners and customers.
Don't get left behind: The future of data is shared
The modern data stack is revolutionizing how organizations manage, share, and leverage their data assets. With Iceberg as its foundation and solutions like Vendia IceBlock enabling secure and seamless data sharing across diverse environments, organizations can break down data silos, foster collaboration, and unlock new possibilities for data-driven innovation.
But the journey doesn’t end here. The data landscape is constantly evolving, with new technologies and trends emerging all the time. In the next and final part of this series, we’ll explore the future of the modern data stack, including the rise of AI/ML, the decline of ETL, and the increasing importance of no-code solutions. In the next blog post, we’ll talk about how these trends will shape the future of data management and unlock even greater value for your organization.