


This article was also published on Medium
The problem: AI access to real-time data
Imagine your boss suddenly gave you a couple weeks off, and you decide you’d like to enjoy a much deserved vacation. To get things rolling, you decide to use an AI travel agent. You convey that you’d like to go somewhere warm, that’s not more than a few hours away by plane, that you don’t want to spend more than $500 a night but you’d like a decent hotel that offers a nice sandy beach you can walk to easily.
To help with a request like this, the AI agent needs to know some basic information, such as where you live in the world and what beach spots are within a few hours plane ride from there. But it also needs to quickly assess a lot of “up to the minute” information, such as:
- What is the weather like right now in those regions (so it doesn’t send you into the middle of a tropical storm)
- What are the hotel rates right now (so it doesn’t exceed your budget)
- What is the flight availability like (so it doesn’t get your hopes up to a destination you can’t actually reach)
This “real-time” information – also known as operational data (because it tends to be the kind of data that businesses need to operate) – presents a problem for AI agents, because it can’t be “baked in” in advance. The underlying LLM (an AI “large language model”) might have been created six months ago, but the weather six months ago isn’t particularly relevant, even assuming the model was told about it at that time.
To deal with real-time data, an AI agent needs to do what a human being would do in those circumstances: Access the actual sources of information on the fly. No amount of “precanned” intelligence is going to suffice, because in the time it takes to load information about hotel availability, flight reservations, weather conditions, and so forth into some database or LLM processor, all that ephemeral information can change, making the precanned version of it at best out of date and at worst dangerously incorrect or misleading.

Figure 1: Various mechanisms to get data into AI agents, from baking it into an LLM (slow, infrequent updates) to RAG approaches (medium update cadence, great for slow-changing proprietary information like documentation), and finally direct data connections, such as MCP, that provide instant access to up-to-date information.
Accessing enterprise data
While some real-time information, such as the current weather in Cabo, can be Googled from the open Internet, most of the operational data that enterprise AI agents need is locked up in the operational systems owned by that company. Customer orders, shipments, inventory, manufacturing projections, payments…every aspect of business processes is ultimately reflected in operational databases and the business applications that update them. Powering AI experiences, whether for internal uses to help manage business operations or external uses such as customer support, requires access to all those sources of real-time information.
While advances in generative AI and AI agents are certainly novel, the challenges associated with accessing, integrating, transforming, and utilizing operational data within and across enterprises is nothing new. Companies of all shapes and sizes have been struggling with getting the right information to the right places to power their business functions since long before computers existed. In fact, for the last several decades, a broad category of solutions has grown up known as “EiPaaS”, or “Enterprise Integration Platform as a Service”. Companies like Boomi, Mulesoft, Workato, and others have built their entire existence around helping businesses connect applications and data together. Public cloud companies have also invested heavily in foundational services, such as API Gateways, that make it easier to “pipe” data between its sources and destinations without having to write a lot of code or hire a lot of engineers just to handle that data flow. Even the databases and datalakes themselves have invested heavily in helping their ecosystems solve the challenges of moving large amounts of data in and out of their respective platforms through technologies like ETL/ELT and reverse ETL.
Given all these long-term investments and mature, in-market offerings for EiPaaS solutions, why would AI need something different? It’s a reasonable question, but let’s first take a look at the common requirements. Both “classic” enterprise applications and AI-based implementations share similar needs for:
- Data Security – Data at rest and in transit needs to be protected from getting into the wrong hands or being intentionally or unintentionally altered along the way.
- Compliance – Customer personal information (PII) and personal health data (PHI) must be protected and all other regulatory requirements pertaining to the data in question need to be met and periodically audited.
- Governance – Access controls need to be in place so that, e.g., sensitive information such as sales performance is only visible to the correct people, processes, and applications that have a need to know.
- Monitoring and Auditing – Problems arise even in the best companies, so mechanisms need to be in place to detect issues such as data that is no longer arriving as expected, and the conditions that might have caused such issues, as well as change management to help understand what was altered, by whom, and when it happened.
- Performance and scalability – Corporate data can change quickly across many systems, and real-world issues such as cancelled flights that require rapid rebooking for many passengers can cause “spikes” in the volume of data while still requiring tight latency requirements to be met. All applications that interact with such data generally rely on the underlying data infrastructure to deliver its information in a timely manner, because slow or out-of-date responses are often equivalent to incorrect ones due to timeliness concerns.
If the needs of AI agents were limited to the conventional requirements above, existing solutions would likely prove just as useful as they have for other enterprise needs over the years. However, AI agents also have some unique challenges that diverge from conventional EiPaaS platform capabilities:
- A mix of synchronous and asynchronous (“callback”) communication patterns – Even though enterprise data is mission critical and high volume, its communication patterns are often relatively simple. In many cases, data simply moves in one direction, such as streaming order information into a reporting system for aggregation and business intelligence (“BI”) reporting needs. However, AI interactions can require simultaneous, bidirectional, and even nested “Q&A” sessions that are unlike conventional enterprise data flows. As an example, imagine an AI agent requesting information on behalf of a user who’s called customer support asking for an explanation of insurance benefits that were only partially paid. In turn, this will trigger a corporate billing system call (probably in the form of a SQL query to a database) to retrieve the information. But to assemble the result into a valid form, the unpaid or partially paid rows of the response might need conversion to “human readable” text, which requires calling back to the LLM to convert each of them into explanatory text before the completely assembled answer can be returned. These “nested queries” needed to assemble aggregate responses are not a supported mechanism in existing EiPaaS systems. AI interactions can also include a complex combination of both queries and commands.
- The need to support prompts as a specialized data type – Existing EiPaaS systems support typical enterprise data types such as strings, numbers, and dates that are normally used by enterprise applications and stored in enterprise databases. But prompts are essentially a new data type of their own, even if they’re represented as strings “under the covers”. Modeling and exposing them directly adds value to the AI applications using them and makes it easier to understand how the service or data being modeled is contributing to LLM answer formulation than if everything were just lumped together with other string-valued corporate data already present.
- Multi-modal resources – Similar to the above, most operational corporate data is expressed as small payloads of simple types, such as strings, numbers, dates. These are usually sufficient to model most business processes, such as “how many nails do I have in inventory?” or “what is in customer order #123?” However, AI agents may make use of more elaborate and heterogeneous data, including spreadsheets, images, textual and binary files, large-scale datasets, and more…sometimes all at once. Handling that level of data variety seamlessly and in parallel isn’t a key capability of existing EiPaaS systems.
- Convenient AI data “firewalls” – This is a subtle consideration, associated with the degree of trust (or lack thereof) placed in AI agents and the answers they provide. LLMs make it possible to combine, emit, and transform vast amounts of information – far more than a single human brain can hope to mentally simulate, estimate, or prepare for. As a result, things go wrong with AI answers (hallucinations, lies) in unpredictable ways, and data can be incorporated into answers sent to humans or other systems in an equally unpredictable fashion. To protect sensitive corporate data and customer privacy (PII, PHI) as well as continue to comply with key regulations and laws, enterprises need to be extremely sure that the information fed to the LLM is “sanitized”. This makes it helpful to have a distinguished system for handling and firewalling that data, if for no other reason than to provide a “one stop shop” when it comes to knowing which corporate systems and what data within them was shared with the AI (and thus potentially to its users).
Enter MCP
To address the unique challenges of data integration for AI applications and agents, Anthropic, a leading AI company focused on safe knowledge handling, recently introduced a framework known as “Model Context Protocol”, or MCP for short.
Anthropic’s official description of MCP is “a new standard for connecting AI assistants to the systems where data lives…its aim is to help frontier models produce better, more relevant responses…[because] it provides a universal, open standard for connecting AI systems with data sources, replacing fragmented integrations with a single protocol.”
In short, MCP is EiPaaS for AI.
What that means in practice is that MCP defines on-the-wire data protocols and a “bridging” mechanism to connect AI agents and other AI-related infrastructure and applications with corporate data that lives in conventional applications, behind internal APIs, and/or in operational data stores conventionally accessed through SQL commands. This information is the type we’ve been talking about: Information about customers, orders, inventory, etc. that changes rapidly, is mission critical to the business, and highly relevant to employees, customers, and partners who are asking questions of the AI or requesting it to take action on their behalf. As a result, it must be accessed in real time versus getting “baked in” to a model or vector database hours, days, or weeks prior to using it.
MCP has three parts:
- Tools – Tools include both queries (information retrieval) and commands (actions taken on behalf of the user). Tools are basically a dedicated API gateway or proxy that sits between the AI agent and the underlying enterprise systems and services.
- Resources – Resources provide a multi-modal solution for retrieving different types of data from a shared namespace, such as photos, data files, or other information. Resources are like the finder on a personal computer or a cloud file directory – they allow large volumes of data to be independently accessed through a hierarchical naming system.
- Prompts – Prompts are a special type of resource that represents AI queries and data formulation patterns specific to the data or system being modeled.
Next, we’ll look at the different parts of MCP and which parties implement them.
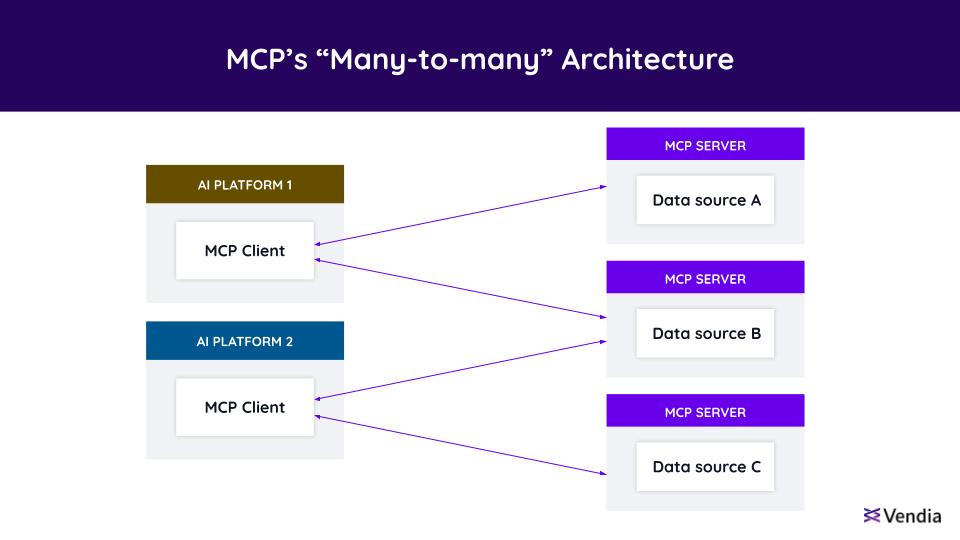
Figure 2: MCP architecture, showing the relationship between clients and servers. Data sources can represent internal databases and applications, SaaS vendors, business partners, public cloud object stores, and more.
MCP architecture
If MCP is the “bridge” between corporate data and applications and the AI agents that represent them, a natural question is who builds this “bridge” (what MCP terminology refers to as a “server”): Is it
- The owner of the data, because they understand the data and its containing systems well), or
- The owner of the AI agent, because they understand what AI infrastructure needs and how to optimize it, or
- A third party because they specialize in building great MCP implementations.
As with any complex enterprise infrastructure, the real answer will inevitably be, “all of the above”. But even though it’s early, a few patterns are already evident. For instance, SaaS vendors will almost certainly consider “wrapping” their existing APIs with MCP equivalents, enabling services such as Stripe to more easily expose their existing information and capabilities related to payments to AI agents and related processes. Similar patterns will likely emerge inside of large enterprises where some department, division, or group naturally owns an existing corpus of data or its associated APIs and services – in this case, MCP is simply another way of “getting to the data”, alongside existing solutions such as APIs, SQL, ETL, and so forth. And of course existing enterprise consulting companies, such as KPMG, will undoubtedly develop specialized practices around MCP development, deployment, and management.
Spanning “Data Canyons”
There’s also another important consideration that comes into play with any data integration needs, but especially for AI-related solutions: What happens when the important information isn’t inside a company’s four walls?
Businesses inevitably need to partner with other companies to deliver customer outcomes – vendors, shippers, financial services, SaaS applications, etc. all represent elements of a company’s business processes and operations. They also represent crucial information about those business and processes and operations that lives outside a company’s own data stores and application infrastructure.
To deliver complete, correct, and up-to-date answers, AI agents and other solutions need access to this partner-held information, which is even more challenging than accessing a company’s own internal data. Data sharing companies like Vendia help solve this problem with data sharing infrastructure designed to synchronize information across multiple parties, clouds, lakes, regions, and systems. Without a platform-based solution, companies need to take additional steps to ensure AI systems have access to this information, such as wrapping remote API calls with MCP in a layering approach, or creating “staging depots” for inbound multi-modal data that can then be exposed as MCP resources.
Fully managed MCP versus “DIY” approaches
MCP is just a protocol – the work of actually implementing wrappers around corporate data, APIs, and other resources is left to every single database or application owner in every enterprise. Given the challenges of turning both internal and external (partner) data into usable MCP servers and ultimately high-quality AI agentic capabilities, it’s natural to wonder if there are any shortcuts available.
While SaaS vendors such as Stripe will inevitably want to write their own custom MCP wrappers to maintain tight control over how (and how scalably) their APIs are exposed to agents, many companies just “need it to work” – crafting MCP servers won’t be directly related to their bottom line, and they will simply want to achieve the necessary AI outcomes at the lowest cost in terms of both staffing and infrastructure spend. Details such as making MCP servers fault tolerant, low latency, and highly reliable will represent unnecessary complications to many would-be adopters, and dealing with challenges like partner data access, cross-cloud, cross-datalake, and cross-region data integration will make delivering MCP options at best difficult and at worst impossible for many small-to-mid sized enterprises.
Open source implementations will eventually appear, with well-tested, reasonably-performing MCP server “libraries” emerging for popular data sources, such as Postgres databases. However, even once the MCP code is available, deploying and managing it on DIY infrastructure will represent an ongoing expenses and staffing requirement. Companies that do want to roll their own – in whole, or just for key parts of their infrastructure – can also leverage emerging practices from consulting companies such as KPMG for assistance.
Fortunately, there is a “short cut” that companies can take to overcome the MCP bootstrap and ongoing support challenges: Choosing a fully managed MCP solution. EiPaaS providers, AI companies, and data platforms such as Vendia are all developing MCP server implementations that connect to common data sources and applications while offloading the cost, complexity, and management overhead of the actual MCP implementations. Using these, as well as the prepackaged offerings emerging from SaaS providers allows companies to enjoy the benefits of MCP and AI agents without the cost of “rolling their own” or solving problems like multi-party data synchronization from scratch.
MCP’s advantages and limitations
One of the key benefits that Anthropic touts for MCP is that it will eliminate the “N-squared” problem, where every SaaS vendor or data owner in a company has to create a different, novel connection to every possible AI agent or infrastructure. The hope with MCP is that each of these owners creates MCP once, and then it suffices for all AI needs, everywhere, over time. Of course, that’s only true to the extent that either everyone adopts (only) Anthropic-based AI technologies or other AI vendors (and all information providers alike) agree to use MCP, which is still very much an open question.
There are also potential alternatives to MCP that could compete with the role it intends to play in the AI ecosystem:
- Existing EiPaaS solutions, because they already solve much of this problem, could incorporate MCP-like capabilities into their existing solutions, making the need for a standalone protocol unnecessary and giving the industry a rapid “jump start” on AI data integration solutions.
- Vector database companies (and conventional databases with emerging vector support), could potentially convince enterprises to simply keep all their data in an “AI friendly” format all the time, eliminating the need to access non-AI optimized systems to retrieve or utilize that data.
- AI infrastructure could get good enough at formulating API calls, SQL commands, and other existing enterprise application protocols that there simply isn’t a need for a specialized bridge at all; essentially, AI agents would become good enough at “being their own enterprise developers” when integrating with existing systems and services to not require anything special at all.
- And of course, alternative protocols that play a similar role to MCP but are promoted by Anthropic competitors, could arise, leading to a “VHs vs Betamax” protocol war.
MCP is also still a very new and relatively immature offering, especially relative to conventional (and well-established) EiPaaS products. Where those tend to offer hundreds of built-in connectors, extensive workflow and transformation engines, debugging and logging facilities MCP has essentially nothing comparable. This isn’t a reason to avoid MCP – it will obviously expand and mature over time – but it is an important set of limitations to understand when attempting to put MCP into production alongside more mature enterprise infrastructure.
It’s also important not to confuse MCP – which is just a protocol definition – with specific implementations of MCP. MCP itself basically just addresses what questions an AI agent can ask of a data owner and how the answers are supposed to be represented in bits and bytes. It doesn’t address how well or poorly that data is modeled, whether all the data is accessible or only some of it, how accurate or informative the resulting AI answers are, or anything else outside of the “data bridge” per se. Nor does the MCP protocol address key operational issues such as throughput, latency, fault tolerance, data sovereignty, auditing and compliance controls, or other key corporate security, privacy, governance, or compliance considerations. These aspects depend entirely on how a given MCP server is implemented, hosted, maintained, secured, and so forth.
Perpetuating data silos: The lack of “join” support in MCP
There are also some deeper, more “structural” limitations that MCP will ultimately need to overcome, even as a protocol. One of the most limiting of these is that it perpetuates existing data silos, meaning that by keeping separate data sources separate, it doesn’t allow for their information to be easily blended or “joined” together.
Joins are some of the most performance-critical operations in an operational database, and for good reason: They have to process potentially millions (or more) of rows of information and compare it efficiently before returning results. Without dedicated join support, MCP’s protocol effectively requires data joining to be done by the AI agent itself. Unfortunately, as with human agents, complex, data-intensive joins are not what AI excels at, both due to the amount of information that needs to be retrieved and compared (and the sheer amount of time and network bandwidth that would require) and due to the complexity of the joining process itself.
While there are workarounds to this, such as implementing “aggregation layer” MCP servers that can combine the results of other MCP servers, these are themselves challenging to implement and support. Over time, MCP will likely evolve more capabilities in this area that enable selection pushing, cooperative join-like protocols, and other mechanisms that make combining and comparing data across sources more efficient than simply leaving it to the AI agent to disentangle.
Practical advice for MCP adoption
Given the novelty of MCP and the rapid pace of innovation in both MCP implementations and in AI agents themselves, what’s the best approach for a company to pursue in practice?
First, it’s important to take a balanced approach: These are still early days for this technology stack, so attempting to place AI agents, an MCP layer, and all the various related infrastructure in place for mission-critical applications is going to be both challenging and subject to high costs as rapid innovation and evolution inevitably create churn at every level of the stack. However, waiting too long to get started could put a company behind the curve and give competitors a leg up. Rather than one of these extremes, start simple and small: Pick one or two outcomes where AI assistance feels beneficial and start experiments now that will enable exploring these technologies, protocols, and tradeoffs at low cost and with limited impact to existing systems and staffing.
Second, don’t overinvest in DIY approaches that will ultimately seem unnecessary as managed solutions arrive on the scene. Unless you’re an AI company or a SaaS vendor looking to expose your existing APIs in the form of an MCP server, waiting to adopt either open source or fully managed solutions from vendors with expertise in data integration solutions is likely far preferable to attempting to become your own EiPaaS solution overnight…an approach that will require outsized investments in data handling and MCP server specifics that may not have great long-term ROI versus simply using an off-the-shelf platform or library.
Also, plan to stay abreast of industry trends related to AI and AI-related data infrastructure. Given the rapid rate of change at multiple levels, different vendor categories may end up controlling more (or less) of this space over time. Datalakes, EiPaaS solutions, dedicated AI companies, public clouds, and a range of startups are all working hard to offer solutions, though none of these categories can claim a complete, end-to-end AI platform as of today.
Finally, think about ways to improve data integration and collaboration regardless of AI needs. Data integration, especially with business partners, has been a long-standing challenge for most companies, and improving data collaboration infrastructure will pay off in multiple ways, not just in terms of supporting AI outcomes or delivering MCP servers specifically. Vendors such as Vendia have been helping travel, supply chain, logistics, and financial service companies deliver better solutions with lower ROI together with their partners, and investing in these outcomes now can help break through silos and set your company up for rapid success when and as AI agents and other AI solutions come online in the future.
Conclusion
In this blog, we’ve explored a new solution for scalable data integration designed to serve AI outcomes: Model Context Protocol or MCP for short. Initially designed and then open sourced by Anthropic, MCP is designed to “wrap” existing multi-modal resources and APIs and expose them to AI agents without the overhead of companies needing to “connect every information source to every AI agent/platform” manually, repeatedly, and differently.
MCP is a protocol, meaning it’s a definition of how to send and receive data, including metadata about how to find MCP servers and what’s available on a given MCP server. It’s not an implementation however; many different MCP implementations will exist, including those from SaaS vendors, open source libraries for popular data sources and public cloud object stores, fully managed platforms from MCP vendors (especially those already operating in adjacent spaces, such as EiPaaS companies), and of course homegrown or DIY implementations that companies create for themselves.
While a good start, MCP has some limitations – it’s neither fully mature as a protocol (and certainly not in terms of the entire ecosystem), nor does it have the sort of complex data integration support needed to join data sources together efficiently as of today. But expect that with time and adoption, more capabilities and performance enhancements will likely be delivered by the MCP implementors and (growing) community.
Finally, take a pragmatic, measured approach to adopting MCP. Recognize that it’s still very early, so exploration, learning, prototypes, and non-mission critical implementations are likely going to be more cost effective and useful at this stage versus attempting full production solutions or “waiting it out” to see what else develops, which could put your organization behind the curve. As part of that learning, spend time evaluating approaches that will deliver high ROI with minimal staffing and infrastructure spend over time, such as fully managed solutions, especially those that can also help with underlying data integration challenges such as secure multi-party collaboration.
The emergence of Model Context Protocol (MCP) represents a significant step towards enabling AI agents to access and utilize real-time operational data effectively. While MCP itself provides a crucial standardized bridge, the practical realization of its potential hinges on robust implementations and the ability to overcome existing data silos. Vendia plays a pivotal role in this evolving landscape by offering a future-ready data architecture that harmonizes flexibility and security. Our platform empowers you to seamlessly move and standardize data across diverse analytical systems and multi-warehouse environments, including support for formats like Apache Iceberg and Delta Sharing, crucial for any AI initiative. By avoiding vendor lock-in and optimizing costs, Vendia provides a vendor-agnostic foundation to activate your AI strategy. To delve deeper into the critical role of modern data platforms in GenAI projects and learn how to protect sensitive information effectively through RAG applications, we invite you to explore our comprehensive GenAI whitepaper.