

As technology takes an increasingly important role in all companies, the way businesses share data with each other has evolved as well. In this blog post, we will review the basics of shared data architecture, how it has evolved, and explore different shared data architecture patterns.
Let’s start by defining “shared data architecture” and unpacking an example use case:
Shared Data Architecture is an architectural style that’s optimized for sharing data across multiple parties in real time. It includes components that are purpose-built for available, timely, and accurate data across a wide-ranging landscape of people, patterns, and tools.
An example use case which it is critical to build a solution that is focused on data sharing is in travel: booking, boarding, and traveling on a ticket.
- You are looking to book an airline ticket on Delta through an online travel agency, Expedia.
- This same ticket is advertised across other online travel agencies, e.g. Kayak.com, cheap-O-air, or the airline’s direct ticketing website.
- As tickets are booked, the availability of seats must be adjusted on all platforms that advertise the ticket.
- When a flight sells out, each agency must receive the latest data to reflect that status.
A use case like the above requires building an architecture that ensures (1) data is shared real-time and (2) shared data is accurate. There are a variety of patterns one might use to realize the vision of sharing data, all of which leverage one or more of a set of basic characteristics.
Shared data architecture basic characteristics
The basic characteristics of a shared data architecture are:
Decentralized. So that no single participant is required to be all-knowing and all-seeing.
Real-time. Changes will be propagated and known to other authorized participants in a continuous manner.
Consistent. The data should be the “single source of truth.” That is, it doesn’t matter which participant accesses the data, the result should be the same.
Ledgered. Data change logs are available with full history of who changed what and when for high traceability.
Access controlled. Participants can only access data they need and nothing more.
One does not need all of them to be considered a shared data architecture, but the more complete each characteristic is build, the more mature the shared data architecture will be.
When creating a solution, teams typically look at these characteristics as part of their requirements, gathering, and design stages. Say a team absolutely needs changes to be propagated to other applications as they happen. That can be accomplished using web sockets, database change data capture (CDC), or even with a streaming solution like Kafka, where consumers are constantly checking for update events. The challenge with these point-to-point options is the lack of a single source of truth across multiple parties, specifically cases where multiple writers can contribute data at simultaneously.
Distributed platforms like Vendia Share, challenge the conventional thinking on point-to-point solutions by ensuring the data is available, updated with all changes, to each participant without anchoring them to a centralized platform.
A more comprehensive definition of the characteristics of a shared data architecture can be found here.
Functions of a share data architecture
The purpose of a shared data architecture is to make data available to the people who need it. All data architecture has four core functions:
Get your data
A mature shared data architecture will make it easy to collect data from various sources. In our previous ticketing example, an end user’s action in the app (say booking for canceling a ticket) needs to, before anything else, captured and accessible to the parties or systems that need it.
Know your data
A mature data architecture will include data and its schema. This schema adds definition to, as the title suggests, _know _what the data contains. In addition, a best practice is to keep a log of all changes over time, enabling one to know all versions of the data. That way, no matter what changes happened over time, you will still know what your data is today and was at any given point in time. Mature data architectures will include both a schema to add definition to the data and history of all versions of, and changes to, the data (or ledger), enabling one to know what the data contains.
Use your data
Data is not valuable unless it is actively used and accessible. Empowering businesses to use their data with ease is a sign of a mature shared data architecture, one that stores and structures data in a way that makes it usable for the appropriate access pattern.
Data that changes only once is a trivial use case. What’s more interesting is a piece of data that is constantly used and changed, through regular queries and mutations. In the ticketing example, imagine the last ticket for the flight was sold but a partner’s app still shows tickets are available – data inconsistencies can kill user experience. This changing data must be _usable _to the end-customer, visible and actionable. To enable this, a mature data architecture must go beyond storing the data but adding definition to _know _it and means to _use _it.
Share your data
To realize the full potential of data, a company often shares it with other teams, partners, or even other companies. Many companies find this aspect of a shared data architecture to be the scariest. They can potentially lose control of the data. While they want to share, they also want to know what others are doing with their data. A shared data architecture with access controls make sharing data with other parties more viable and can enforce minimum needed access for all participants.
See how other data architectures perform these functions here.
The evolution of shared data architecture
In the modern world, electronics and the internet take prevalence over other forms of data storage and transmission. From physical folders to Google Drive folders, from indexed shelves and drawers to indexed relational databases, from encoded mapping to blockchain technologies. We can see that many concepts were very similar. But what has changed is the level of efficiency and how fast calculations can be done to make these patterns more useful to use nowadays.
Types of shared data architecture patterns
Let’s unpack the various architecture patterns for enabling data sharing and break down which of the basic characteristics they best support.
Point-to-point sharing

Just as the image shows, this pattern requires each participant to send their data to each other to ensure all data is kept in sync. Example implementations include:
- Emailing between participants of Excel sheets (people would be surprised on how often this is still the case)
- CSV files delivered to certain servers and then processed to multiple downstreams using batch jobs
- Integration Platforms (iPaaS) that gets data from multiple platforms and then sends data to each target. This is a more up to date approach in this pattern.
| Decentralized | Real-time | Consistent | Ledgered | Access controlled |
|---|---|---|---|---|
| High | Low | Low | Low | Low |
| Each Party will hold a copy of data to use. | The process is not continuous and often triggered manually, with each integration point having its own schedule. | It’s hard to keep track of the most up to date version of the data with duplicative logic needed for each integration point. | These solutions don’t track data changes over time nor who made the changes. | Typically, it’s a none or all approach. As the data is sprawled across each integrating system, there is a loss of visibility in who has access to what data |
Centralized Hub
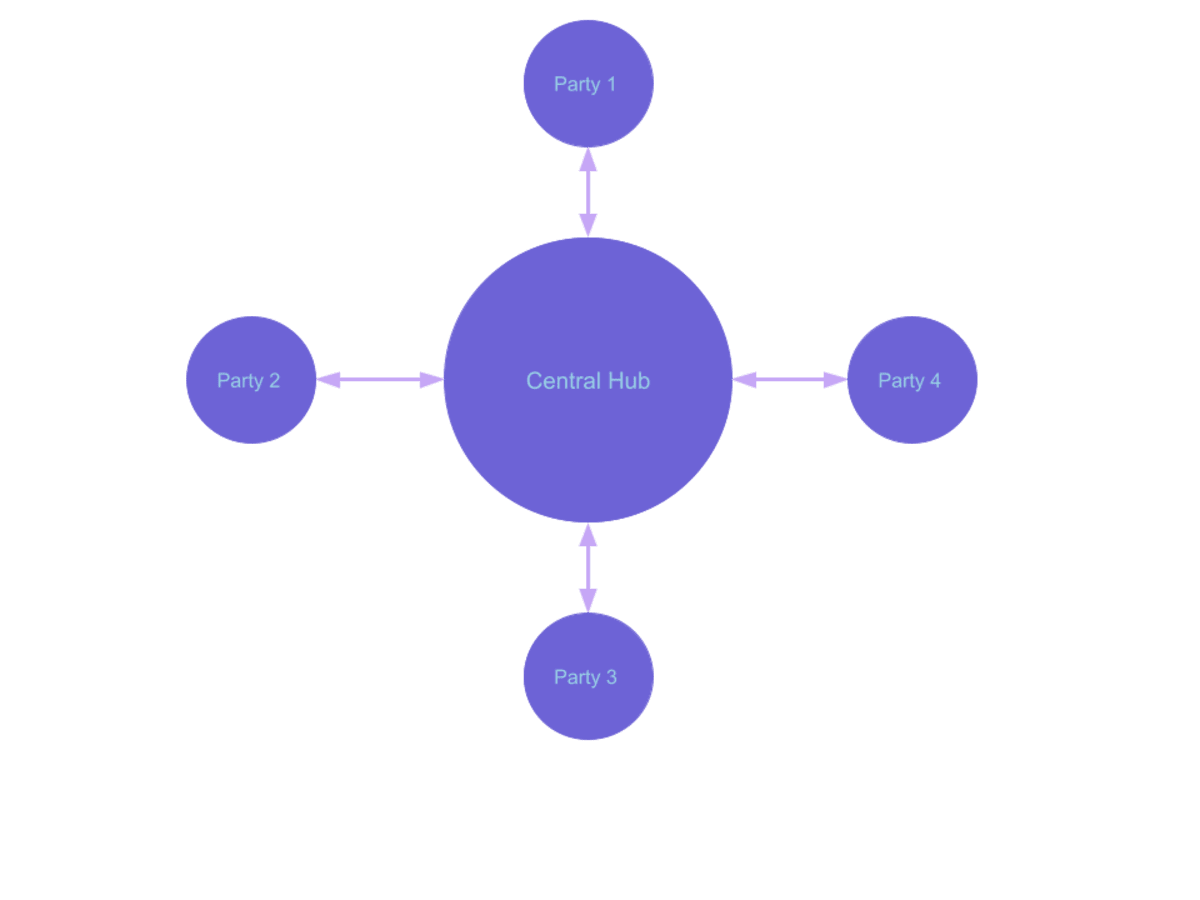
When data is scattered across multiple sources and multiple parties need some portion of the data to do their job, it makes sense to pull data from those sources and store them together in a single centralized system.
One of the challenges with this pattern is that anything changed in the central node will not be propagated to the original sources, which creates inconsistencies in the data. Another challenge is that the centralized hub, and the development team supporting it, often takes responsibility for translating data from each (distinct) source system, which can be complex and costly to maintain. However, it is very convenient for a data consumer to have all the data they need in a single place.
Some examples include:
- Enterprise data hub
- Operational data store
| Decentralized | Real-time | Consistent | Ledgered | Access controlled |
|---|---|---|---|---|
| Low | Medium | Medium | Medium | High |
| Centralized hub is meant to put all data in a central location for efficient processing. These solutions have similar drawbacks to the traditional “monolithic” architectures. | Many of these hubs utilize connectors to connect to platforms continuously. | There is no general consensus across participants. | Often the hub does not have change logs for the data. | The hub itself collects all the data and we can set up limited access to that data. |
Real-time data sharing
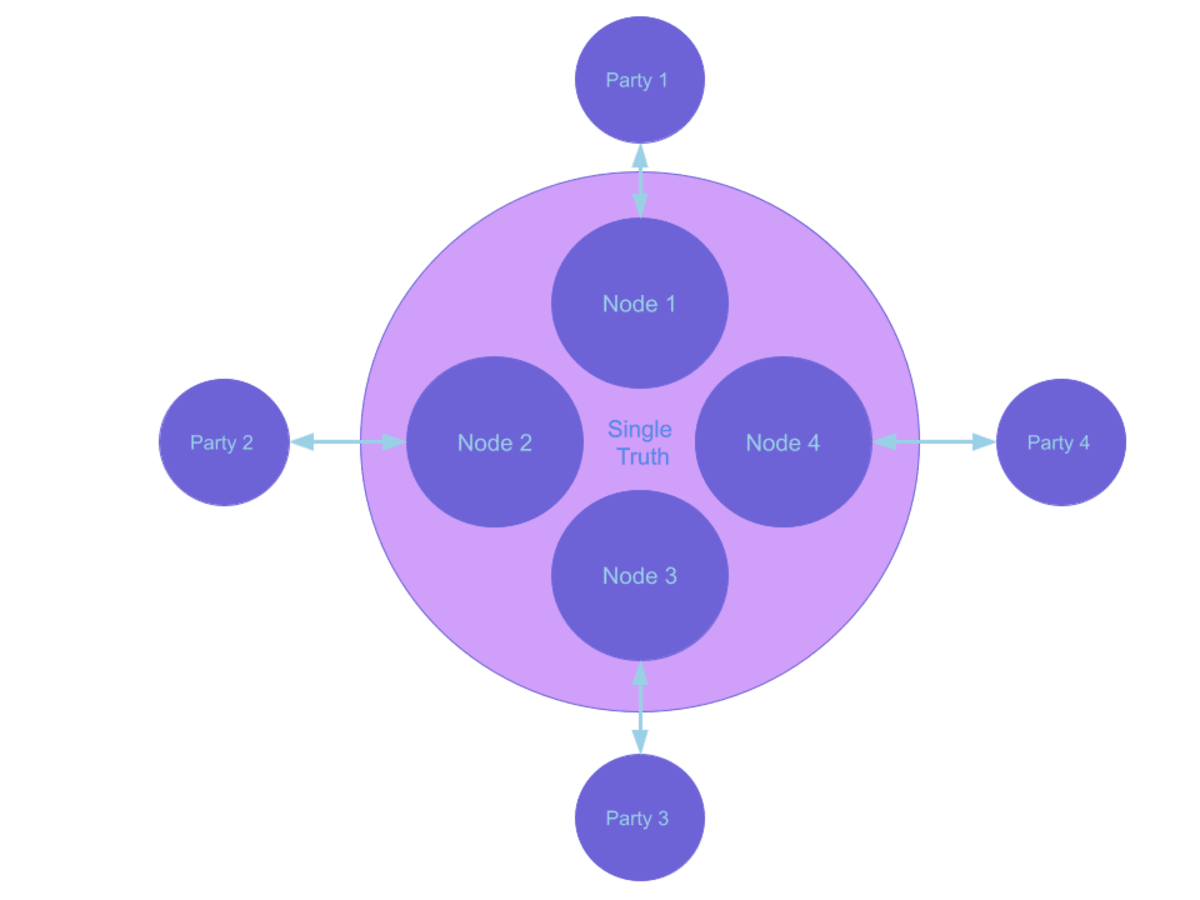
As its name suggests, this pattern shares data with multiple parties as it happens. But typically in a decentralized, ledgered, and consistent manner with access control to limit participants to only what they need. A mature real-time sharing includes considerations for both the data itself and the history of data changes. Not only is the process continuous, it allows each party to modify data as required. In addition, it allows all participants to know about a change as soon as it happens. Such a pattern could be achieved with building databases with change data capture (CDCs) and Kafka in the picture. But that is not the most cost effective setup nor is it trivial to set up a scalable Kafka cluster. Also, they require additional layers of integration to consume the CDC data, parse it, and apply the changes to have a consistent definition of the data across all parties.
But it can, however, be done in under 5 minutes with Vendia Share.
| Decentralized | Real-time | Consistent | Ledgered | Access controlled |
|---|---|---|---|---|
| Medium | High | High | Medium | Medium |
| There is no guarantee of decentralization in implementation. | Any changes should be continuous and synced across all resources. | The data should be in sync with other replicas. | This feature is not necessarily in all implementations. | Security is one of the things that’s typically hard to be built right. |
Vendia’s real-time sharing
| Decentralized | Real-time | Consistent | Ledgered | Access controlled |
|---|---|---|---|---|
| High | High | High | High | High |
| Same data will be held across multiple nodes. All nodes can be read and written. | Changes can be picked up continuously without human intervention. | Data is consistent across all nodes to provide a single source of truth. | All data changes logs are available for compliance audits. | Access can be limited by various aspects to ensure minimum required access for each participant. |
Shared data: point-to-point or blockchain?
At Vendia, we believe that the future isn’t about databases versus blockchains, but rather that they will exist as a single, unified data abstraction. That is we believe blockchains and databases will eventually collide and converge.
But the ultimate question still remains. With all these different approaches and patterns, which ones are best fit?
To answer this question, we need to figure out exactly what is required.
We typically start asking these questions:
- How important is high availability?
- Do we need the sharing to be real time? That is, do all parties also need to be able to modify data and have respective parties receive the latest version based on my updates?
- Do we only want a single source of truth? Is the consistency of changes made by all participants required to be broadly aligned?
- Is change log important for us? Do we want to keep track of every version of our data update?
- Do we want fine grained access control to all participants so that they only have access to what they need?
If the answer is YES to all these questions, then Vendia Share is probably something you would like to try out first by building a PoC in the next couple hours.
The more NOs we have to these questions, it opens up more options to other tools. But also bear in mind that it means we will deviate away from best practices as well. Point-to-point solutions make data available and real-time, where Blockchain solutions make it consistent, ledgered, and (with the right tool) access controlled. Often, neither of these solutions meet all the above questions, unless there is a tool purpose-built to bring the availability of point-to-point and the immutability of blockchain.
Vendia’s approach to shared data architecture
Setting up an advanced shared data infrastructure is not easy. In fact, many have either failed or required expensive solutions to build to still not get quite there. Vendia Share strives to make blockchain and shared data architecture adoption easier. So our customers can focus on what matters most to them rather than building expensive (in time, people, and dollars) infrastructure. Vendia provides all the characteristics discussed above.
- Decentralized. Vendia’s Unis are cross-cloud and distributed, but still offers a single version of truth
- Real-time. Any changes made by any party is available to all nodes and usable by front-end applications through the GraphQL API.
- Consistent. Vendia ensures a single source of truth with reconciling updates made by all parties across all nodes. that includes consistent data validations, consistent transaction ordering and execution.Once consensus is reached between all nodes, global state truth can be retrieved from each node by choosing appropriate readMode.
- Ledgered. Full, immutable history of who changed what data and when, allowing for compliance in audits and rebuilding the world state for resilience.
- Access controlled. Capability to dynamically manage access rights, ensuring each participant interacts with only the data explicitly shared with them.
On top of these notable features, Vendia has achieved several database specific characteristics. We have achieved high availability (currently 99.99%), Zero Ops (fully managed by Vendia) for customers, and query language availability (GraphQL supported).
We are the leader in database and blockchain convergence and represent the next-gen blockchain. In addition, as it was pointed out in the previous table, Vendia excels in offering all the characteristics of a shared data architecture.
Next steps
If you’ve read through this far, data sharing probably has been a pain point for you. Every industry continuously evolves over time. The technology sector has been among the fastest of them all. To ensure you are staying ahead of the curve and keep informed of what the newest technologies can do, it will definitely be worth your time to sign up for a trial version of Vendia and get a feel of real-time sharing.