


This article was also published on Medium.
In the previous blog post, we introduced the foundational layers of the modern data stack: the app layer, the data lake layer, and the storage layer. Now, let’s dive deeper into how these layers are connected to maximize performance and minimize complexity for end users.
Connecting the storage and data lake tiers: Iceberg as a “universal glue”
A key aspect of this connectivity, particularly between the data lake and storage layers, is Iceberg. As a standard data format and data access technology, it allows a new level of interoperability and portability – both vertically between layers of the modern data stack, and horizontally across an increasingly heterogeneous set of vendors, providers, and toolsets. In short, Iceberg is the “glue” that holds the modern data stack together. In particular, at the middle (data lake) layer of the stack, Iceberg tables can be referenced through what are known as “external” table references. Here, “external” is code for “portable and stored outside the data lake’s internal mechanisms”. This direct access is fundamental for efficient data sharing, eliminating the need for cumbersome and often lossy transformations: Instead of having to literally move data in and out of proprietary, internal storage associated with each data lake, all data lakes simply reference the data from a common spot (often an Amazon S3 bucket, but in principle any of the options at the storage layer of the stack). It turns out this approach also facilitates data sharing among different parties, which we’ll explore in later installments.
Connecting the application and data lake tiers: Zero ETL as an emerging paradigm
While Iceberg is an important step forward, and the ideal way to connect the storage and data lake tiers of the stack, connecting the top two tiers – the application layer and the data lake layer – presents a different set of challenges. Historically, this intersection has been the domain of ETL (Extract, Transform, Load) technologies and its counterpart, reverse ETL. While fully managed tools have simplified the ETL and reverse ETL processes over time, these mechanisms still often involve manual steps and dedicated operational staffing to deal with the time-consuming and error-prone processes of integrating, refreshing, and error checking all the data copying treadmill. Furthermore, the sheer cardinality – the vast number of operational databases, SaaS services, and applications – makes managing multiple data pipelines a significant hurdle for organizations of any size.
To address these complexities, the concept of Zero ETL is emerging. By shifting data-centric tasks from end-users to service owners, Zero ETL aims to streamline data pipelines and minimize the need for manual data copying steps. The core idea is that data storage can reside directly in the customer’s data lake, eliminating the need for constant movement and synchronization. Instead of building their own complex, proprietary data storage backend, SaaS offerings like Salesforce or Hubspot can simply rely on a data lake’s capabilities, so that users don’t have to worry about shuttling all that information back and forth every day.
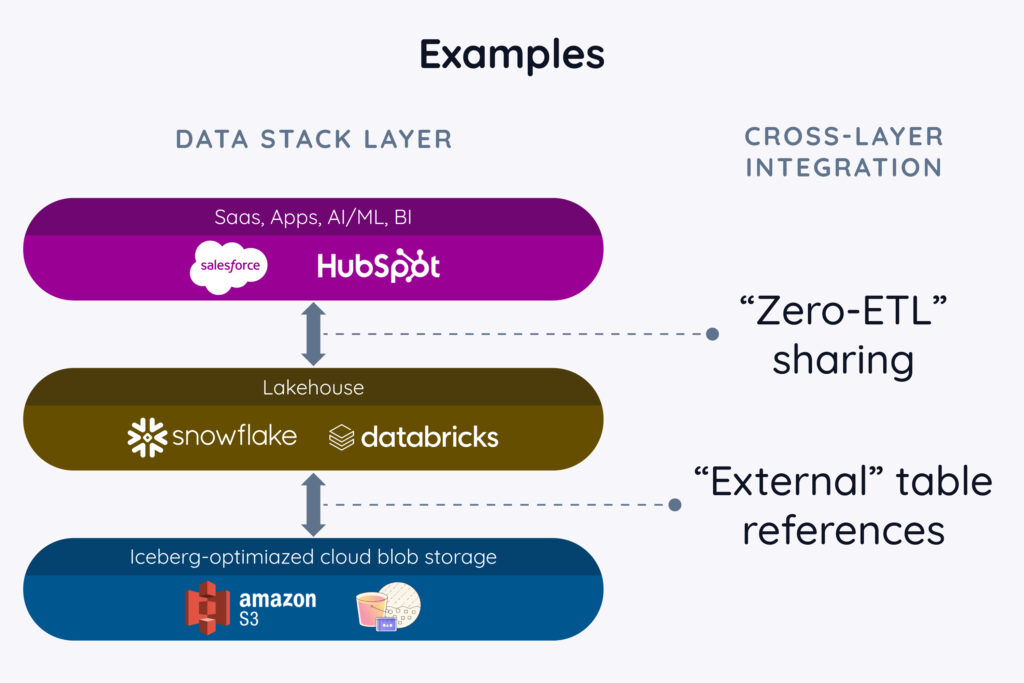
Today, Zero ETL exists in specific scenarios, such as within a single cloud platform (e.g., AWS Aurora to Redshift), between SaaS offerings and a public cloud (e.g., AWS AppFlow), and between select partners (e.g., Salesforce and Snowflake). Over time, the reach of Zero ETL is expected to expand, offering a more efficient and cost-effective alternative to traditional ETL.
Applying the pattern: Zero ETL as a design goal
Organizations can also make “Zero ETL” a design goal when creating new or updating existing DIY applications. Typically creating a new enterprise application that creates or modifies operational data, such as inventory, customer orders, sales, etc. adds even more burden to the analytical side of the house, as the new or updated data now needs to find its way to the organization’s data lake. In short, every operational system and database needs to be “shadowed” with ETL processes, staffing, monitoring, management, security and compliance reviews, and the like to pair it with downstream analytical capabilities needed for BI, reverse ETL-based optimization, AI needs, and more.
Zero ETL architectures instead look for ways to keep the data lake up to date as part of an application’s intrinsic operation, lowering or even eliminating the need for data movement tools like ETL and reverse ETL. While approaches and technologies are still emerging, this can take several flavors:
- Choosing a hybrid operational/analytical data storage solution offered by the data lake, rather than a conventional operational database. In this case, the data starts and stays in the data lake tier, so moving it there is no longer a requirement.
- Using a cloud object store as the storage layer, ideally in Iceberg format. In this case, the data is already in a location where the data lake can simply reference it, without copying, moving, or reformatting the data.
- Building ETL directly into the application, in the form of Iceberg updates. Often an application owner has the best knowledge about data freshness, refresh rates, and of course the underlying data model or schema. Building (ideally, Iceberg-based) updates directly into the application’s logic can therefore achieve the effect of ETL with significantly lower costs than if it has to be reverse engineered and operationally managed and staffed by a separate data ops or data lake-focused team. Emerging technologies from the open source Iceberg community are also focused on making both updates and operational-style tables faster and easier to handle when operating on Iceberg-formatted data.
Bringing it together: Minimizing data movement and ETL overhead
The successful operation of the modern data stack, and its ability to facilitate data sharing, relies heavily on the combination of Iceberg and Zero ETL, which together remove historically complex integration challenges between layers. The ultimate goal here is to enable the entire data lifecycle, where data originates in operational systems, flows effortlessly through analytical processes, and empowers human insights, AI decisions, and automated controls – all without the need for any data replication or migration. This “data copying nirvana” doesn’t exist yet, but it’s clearly where the industry and providers are focused on going.
Centralized control with an Iceberg-based catalog (Polaris)
As a data storage format solution, Iceberg solves several related problems by offering a common way to handle:
- Physical data layout
- Incremental updates
- Multiple versions (snapshots) of data over time
- Transactional integrity (i.e., addressing what happens when two or more tools attempt to update data simultaneously)
- Data schema (aka data model) representation and evolution over time
and more. But solving these challenges alone is only part of the problem. Organizations, operators, and automated systems also need to accomplish management and governance related activities such as:
- Discovering which tables exist
- Tracking updates and changes over time, and notifying appropriate users and systems when they occur
- Understanding when and how data models change and what to do about it
- Correctly classifying data, including compliance, regulatory, legal, or other restrictions or considerations on its use
- Understanding where data came from (lineage) and where it went (sharing and access controls and logs)
and more. These are the job of data catalogs, and fortunately the modern data stack has a solution here as well, in the form of Polaris, an open source catalog designed to offer these services for Iceberg-formatted data.
Acting as both a directory and a “central nervous system”, the data catalog provides a unified view of data assets across the entire stack, making it possible to know what data is available for sharing and how to access it. It also provides a place to track data sharing (which we’ll explore in detail in the next installment), data classification, and data lineage.
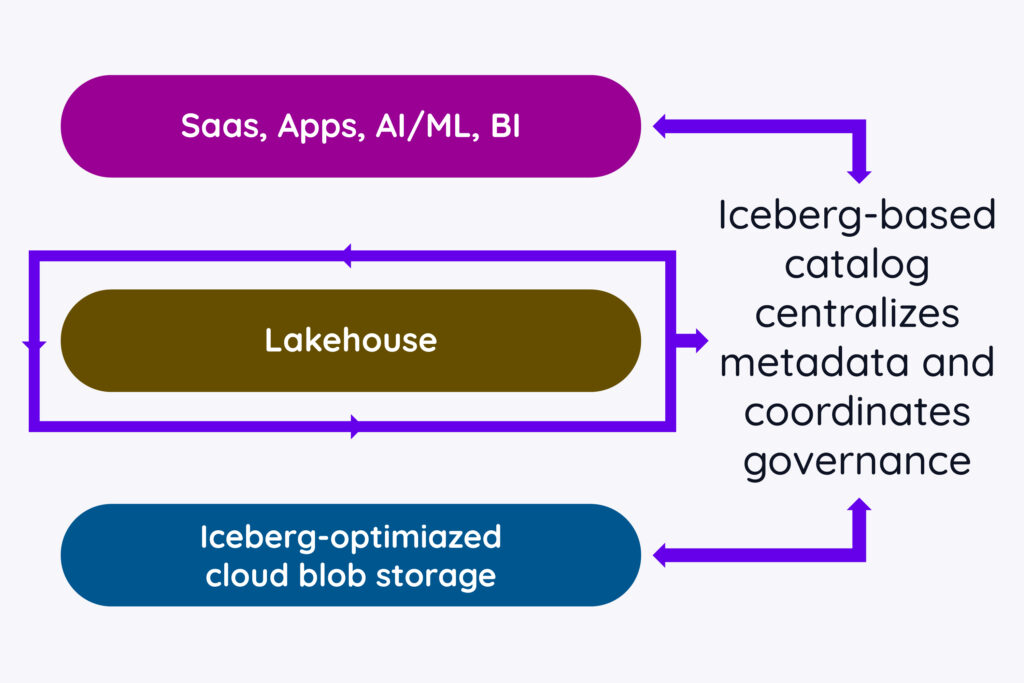
The data lake layer is the preferred location for this Iceberg-aware catalog for several key reasons:
- Lower layers are too granular, dealing with individual files rather than higher-level data operations. While separate storage-layer indexes and governance obviously need to exist, they are not ideally suited to help users and automated systems understand information at the table and dataset level of abstraction.
- The data lake layer is where most data operations and intra-platform sharing occur, making it the ideal control point. It offers both the ideal level of abstraction and high affinity for related activities, such as table-based access controls, lifecycle activities, and logging.
- The application tier is too diverse, making a unified catalog across hundreds of apps and services impractical, particularly given the high level of heterogeneity in their corresponding UIs, APIs, security protocols, and so forth.
This strategic placement in the “middle tier” ensures the catalog has the necessary access and visibility to manage and govern data effectively across the entire modern data stack.
Open or closed? Choosing an approach
While the data lake layer is the ideal placement for a data catalog and associated functionality, there is still a choice to be made between open technologies such as Polaris and proprietary solutions from individual data lake vendors. The latter has some clear advantages in the near term, including the obvious ability to manage non-Iceberg tables and related services. Over time, however, an open catalog offers similar advantages to open data formats: Easier and lower cost portability, less vendor lock-in, and the ability to take advantage of a large and growing set of libraries, tools, and managed solutions that all “piggyback” on the industry standard approach. Eventually, most data lake providers will start to conform to the Polaris standard in the same way that they have with the Iceberg standard, but understand that this is a work in progress and may take several years to reach fruition, especially given the tight coupling between data catalogs and data lake governance and control mechanisms that have historically been implemented in a very proprietary manner.
Data harmony: Orchestrating the modern stack
In essence, the modern data stack functions as a well-orchestrated system, with interconnected layers and centralized control. Iceberg and Zero ETL are the key integration technologies, streamlining data access and operations. The Iceberg-based catalog, residing in the data lake layer, acts as the conductor, ensuring harmony and coordination.
This integrated architecture directly benefits data governance and management by:
- Improving data discovery: The centralized catalog makes it easier for users to find and access the data they need, regardless of its physical location.
- Enhancing governance: Centralized control ensures data is managed consistently and securely, adhering to organizational policies and regulations.
- Streamlining operations: The catalog simplifies data management workflows by providing a single point of reference.
By embracing these technologies and architectural principles, organizations can break down data silos, foster collaboration across various analytical systems, and unlock the full potential of their data for analysis and sharing. The modern data stack is more than just tools; it’s an integrated ecosystem designed for efficient and effective data management and sharing.
What you can do
As vendor selection and application (re)design opportunities emerge, have your organization embrace long-term trends that lower costs and improve flexibility. Zero ETL solutions, whether they come from SaaS providers or are architectured internally, will lower long-term R&D costs and the need for additional ETL-based processing and staffing. Adopting Iceberg-aware solutions and tools will leverage the billions of dollars being invested by the industry at large and help protect against the downside of proprietary or short-lived solutions.
Conclusion
As we’ve explored, the modern data stack provides a powerful framework for managing and utilizing data, built on a foundation of open standards and a layered architecture. Understanding these fundamentals is crucial for organizations looking to unlock the full potential of their data assets.
Looking ahead, one of the most transformative capabilities of the modern data stack lies in its potential to revolutionize how data is shared – both internally and externally. In our next post, we’ll delve into the various approaches to data sharing within this evolving landscape, examining the challenges and opportunities it presents for collaboration and innovation.