


This article is also available on Medium
We definitely are living in ‘interesting times’ for data and data management. Rapid innovation in infrastructure technology, de facto standards emerging industry wide, and new architectural patterns gaining traction are changing the entire data stack. These changes are having a huge impact on how the teams who produce, consume, store, and work with data approach their next gen architectural decisions and vendor selection, and are even changing who can successfully work with complex data at the solution level.
Alongside all the usual IT pressures to “do more with less”, security, compliance, and time to market considerations, there’s also sea change coming in requirements: The advent of GenAI-powered everything in the enterprise. AI-driven insights are only as complete, trustworthy, and relevant as the data used to power them, regardless of whether that’s through domain-specific “custom” LLMs, RAG-based architectures, or AI-driven query and API construction.
The rapid pace of data technology innovation in the presence of what’s shaping up to be the most revolutionary new enterprise use case for data (GenAI) offers exciting possibilities, but it also brings significant challenges to every professional involved at every level. Classic data challenges are also still there – fragmented and siloed data, aging data solutions, and early generation technologies – but the pressure to deliver AI solutions quickly and safely is rewriting the standard IT playbook, since a failure at the data infrastructure and sharing level will inevitably place downstream AI initiatives at risk.
When navigating this shifting landscape, companies face critical questions about their data infrastructure, particularly around how to effectively break down data silos and share data across different systems, clouds, data warehouses and data lakes. Additionally, what is the optimal approach to data governance in this evolving landscape? To address these challenges, organizations need a robust and adaptable framework for managing their data assets.
The modern data stack is emerging as a powerful antidote to both classic problems of vendor lock-in and “data sprawl”, promising a new era where data flows freely and can be leveraged effectively across the enterprise. Often defined as “a combination of various software tools, processes, and strategies used to collect, process, and store data on a well-integrated cloud-based data platform,” the modern data stack offers an improved approach to managing, storing, and sharing data versus what came before. This series will explore how this evolution, built on foundational layers and driven by open technologies like Iceberg and Delta Share, is fundamentally changing how we approach data, with a key focus on enabling seamless data sharing.
Fundamentals of the modern data stack
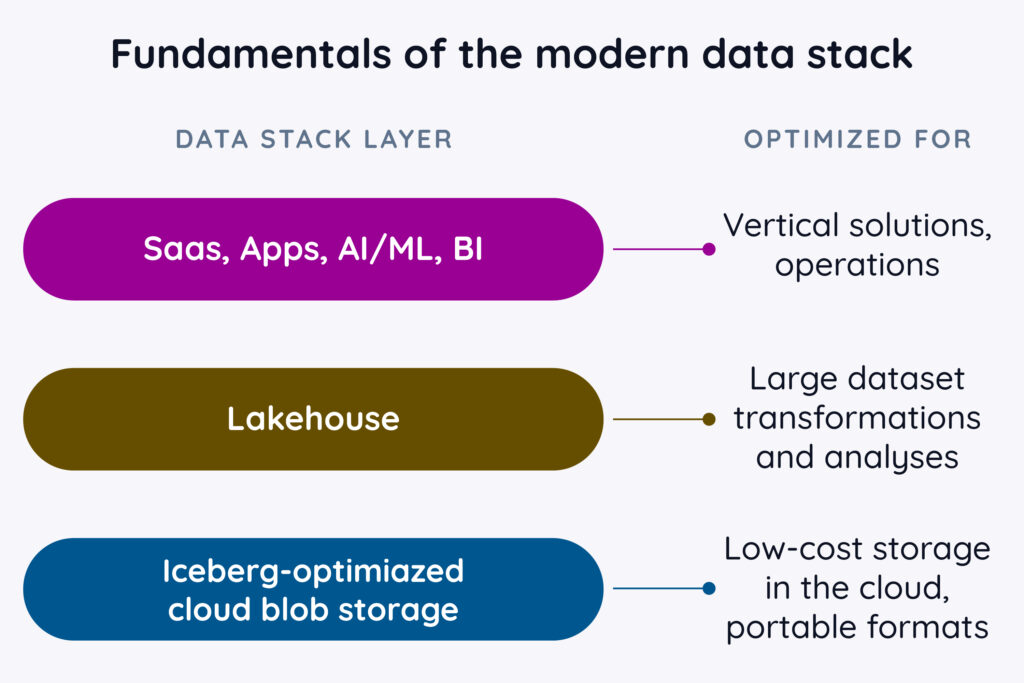
The modern data stack provides a framework for managing and utilizing analytical data (more on how this is also changing in later installments), comprising three distinct layers:
- App layer: This layer focuses on solutions, encompassing operational systems, in-house apps, third-party SaaS, and classic analytical tools like Tableau and PowerBuilder. It’s also where many companies will experience GenAI demands on data, as AI-related services, tools, SaaS features, and more come online.
- Data lake layer: This layer is a modern lakehouse optimized for data-centric operations, including AI and ML capabilities, and with strong support for public cloud integration. (These may also be “native” data lakes that were themselves born in the cloud.) The traditionally narrow focus of this layer on just “analytical” data is rapidly broadening to include additional AI-optimized capabilities and real-time “hybrid” operations that combine elements of both operational and analytical approaches, such as offering quick insights into data from operational sources to power AI recommendations inline with user browsing or service call experiences. This layer also houses what is likely to be an Iceberg-based catalog for many companies, acting as a “central control point” that assists with needs such as data classification, governance, lineage, security, and management/monitoring.
- Storage layer: This layer is a cloud blob store offering low-cost, cloud-native storage. Already, Amazon has made available an option that goes beyond low cost and ubiquitous access to also include Iceberg-specific performance enhancements with some common (formerly DIY) management functions “built in”. This layer provides openness and portability, replacing the old “walled garden” of proprietary, lakehouse-specific data formats and storage tiers. For companies who require both on-prem and cloud data storage solutions, this tier will also include even lower-cost/lower latency on-premises storage to augment the scalable but more expensive cloud storage option.
Critical takeaway: The beginning of the end of “walled storage gardens”
Historically, data lakes and warehouses often relied on proprietary data storage formats, creating “walled gardens” that limited data sharing and interoperability between different systems and tools. This lack of openness hindered collaboration and made it difficult for organizations to fully leverage their data assets and of course made switching between vendors painful and expensive – potentially an advantage to a data lake vendor, but a disadvantage to its customers.
That world is rapidly disappearing, with the storage tier being recast as public cloud blob storage as a “universal storage system”. Unsurprisingly, AWS, Microsoft Azure, and GCP have the lion’s share of the public cloud blob storage under management. At the time we’re writing this in April of 2025, there are still some remaining functionality gaps in data lakes where “native” representations offer more capabilities, management options, or performance enhancements than so-called “external” tables that reside outside their system in (e.g.) an Amazon S3 bucket. But those differences are rapidly disappearing as vendors see their customers embracing this storage approach, driving the market and its product feature sets clearly in the direction of openness.
Greater data portability, easier data sharing, and lack of (or at least, lowered relative to historical norms) vendor lockin from data lakes are all good things. But it’s easy to miss the other big win here: The standardization of a common data format across the entire industry, and benefits every company gets through amortized investments in a single data format and its associated tools, services, catalogs, and APIs.
Innovation alert: Iceberg is the foundation of the modern data stack
In case you missed it, there was a “VHS versus Betamax” war of sorts between two popular analytical table standards: Iceberg and Delta Share, each backed by a powerful lakehouse company (Snowflake and Databricks, respectively). The debates, and especially the ne necessary plurality of solutions in the absence of consensus around who would be the winner delayed the industry’s adoption of a single approach for several years. But with AWS now standing clearly behind Iceberg and Databricks purchasing Iceberg-based startup, Tabular, the winner is clear, paving the way for rapid industry consolidation on Iceberg.
As an open-source data format, Iceberg enables a standardized way to represent large datasets (up to terabytes in size, and potentially beyond), with efficient querying and analysis capabilities. Iceberg’s open nature and portability have broken down the “proprietary format” barriers, allowing companies to more easily share, access, and analyze data across different platforms and tools, many of which already support Iceberg (and others that are rapidly catching up by adopting and supporting it). In upcoming posts we’ll delve into why an industry standard is so important and specifically how it allows for the existence of the modern data stack.
Conclusion: Embrace the open data future
The modern data stack, built on the foundation of Iceberg, represents a significant shift in data management. Its layered architecture and open data format provide a flexible and scalable solution for organizations looking to harness the full potential of their data. By breaking down the “walled gardens” of proprietary formats, the modern data stack fosters collaboration and unlocks new possibilities for data sharing and analysis.
As organizations navigate the evolving data landscape, embracing the modern data stack is crucial for staying ahead of the curve. The transition to Iceberg and the adoption of a layered architecture can empower businesses to leverage their data assets more effectively, drive innovation, and gain a competitive edge in new challenges like AI-related data infrastructure…but only if they start preparing now, with a firm understanding of what’s coming and why.
In the next blog post, we’ll explore how the layers of the modern data stack are connected and how control and governance can be achieved. We’ll also dive deeper into the role Iceberg and Zero ETL approaches play in integrating the stack vertically across layers and horizontally across other systems, all while enabling seamless data management.