


Generally speaking, to build a network, one organization has to take the first step by deciding whether an existing data sharing network requires improvement or whether the partnerships would benefit from a new data network.
In practice, most data networks tend to look like a hub and spoke model, even if the parties involved are equal in a legal or technical sense (Figure 1). This is as much an operational and pragmatic observation as a comment on relationship structure. Data networks expand in three ways:
- Hubs growing more spokes over time
- Existing hub and spoke ecosystems adding new use cases
- Spokes that convert into hubs for their own partner ecosystems
Figure 1: The hub and spoke model for initiating and growing business data networks
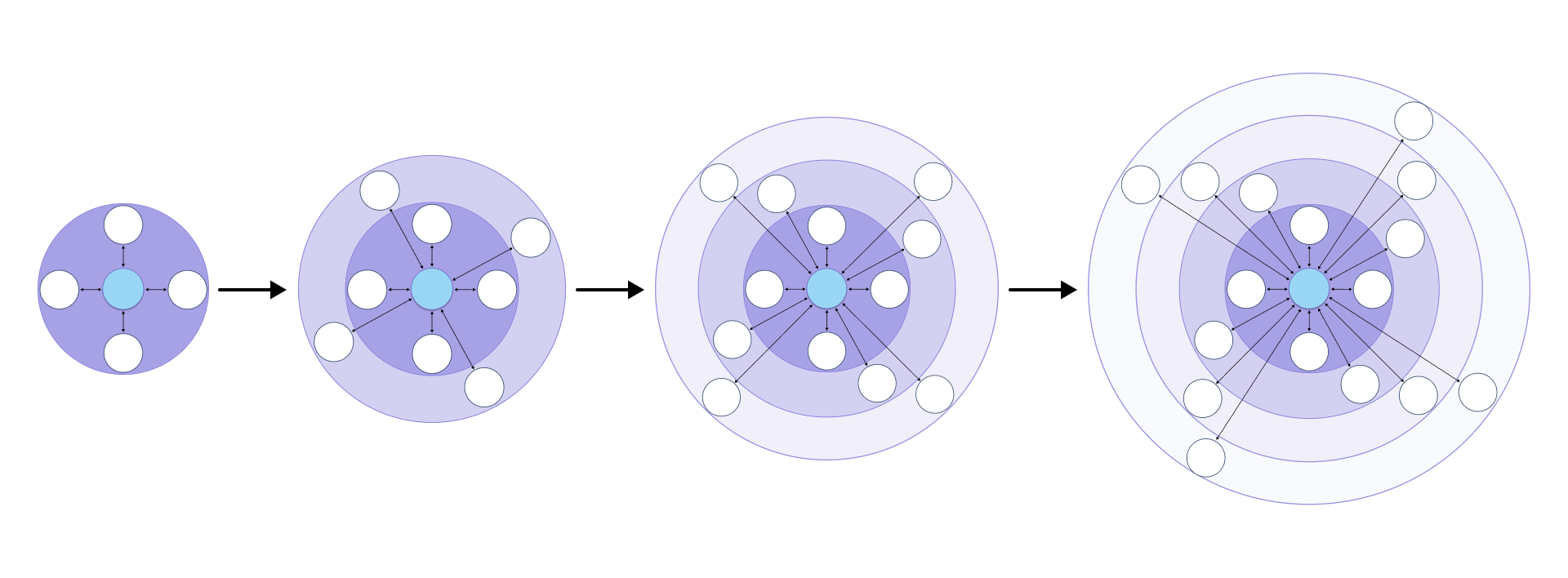
Most data networks tend to look like hub and spoke models with hubs growing more spokes and spokes growing more hubs. All the while, they’re creating new use cases for their business network partners.
Adding partners to your data network
First, additional partners (more spokes) can be added around an existing hub. These partners could be entirely new. They may also have shared limited data in the past or used low-tech solutions such as ad hoc file sharing. However, they now see their competitors or partners gaining benefits through data network participation and want to join in.
Adding more use cases to a data network
Existing data networks can also expand their set of use cases, essentially evolving their data models to embrace additional scenarios or business needs. For example, loyalty program partners who already share customer data may begin sharing sales or purchase data to accelerate their joint programs. This type of growth keeps the partner topology intact, but it creates more value from those existing relationships.
Creating more hubs in your data network
Finally, participants in an existing data network (spokes) can launch new networks of their own (more hubs). These new ecosystems leverage a company’s ability to add value or data they uniquely possess. Having established momentum with data platforms, companies forming new hubs can move quickly to tackle other forms of cost takeout, address additional business needs, or capture emerging market opportunities at the center of their own data network.
No ecosystem of significant size or scale replaces data sharing processes overnight. But incrementality and fast time to ROI are key.
With all these motions, incrementality and fast time to ROI are key. No ecosystem of any significant size or scale replaces mission-critical processes like data sharing overnight. Improving the accuracy and timeliness of data sharing, even between just two parties, is a beneficial first step. It’s also a step that other networked parties can observe and build upon over time when the underlying platform makes it easy.
But, to be successful, the data platform needs to have two critical characteristics: SaaS delivery and automated partner data population.
A data network through SaaS delivery
Adding a party as a new spoke to a network is somewhere between slow and impossible. A new “spoke” requires months of laborious infrastructure, software deployment and testing, and complex network security analysis and integration. It also needs new staffing to deliver on all of this.
On the other hand, SaaS-delivered platforms sidestep these complexities and overhead, keeping initial costs low and offering rapid exploration and easy, incremental commitment to the data sharing approach.
Automated partner data population in a data network
Beyond just being SaaS in its form factor, there’s also a critical step that requires automation when a new partner is added: backfilling shared data.
Generally, for the newly added partner, some historical data must be made available to them, while other (privately shared) data needs to be redacted from them. Getting this correct, and just as importantly, automating it and avoiding downtime on any party’s behalf, is a critical dimension of a successful data platform.
It’s exactly the sort of high-end platform feature that would typically be missing in a “DIY” sharing approach. But it’s economical to deliver in a SaaS platform because the investment benefits many customers and can be amortized across them.
The four phases of building a data sharing network
While data sharing networks are often part of a broad, long-term vision, it’s critical to start small with practical, clear outcomes and a modest number of parties (usually two or three). Working first with a small number of companies allows you to work on details like the data modeling approach and, simultaneously, establish trust in the process and the platform. Generally, domain- or industry-specific best practices emerge early in the process. They can then be shared with additional partners (spokes) as they come on board, lowering their risk and adoption costs.
While these processes vary with the nature of the companies and use cases involved, they tend to follow a four-phase process:
- Phase 1: Hub proof of concept (POC) – In Phase 1, the hub leverages the data sharing approach for an internal project, typically one that involves sharing data across two or more of their divisions, across clouds or regions, or from two or more existing incoming data sources. The goal of the POC is to establish the validity of the data platform and better understand its modeling and deployment tools.
- Phase 2: Initial launch – In Phase 2, the hub and one or two additional parties (the first “spokes”) launch an initial solution together. Phase 2 is characterized by an agreed-upon data model among these initial parties (one flexible enough to accommodate additional parties as they come online in Phase 3 below). Phase 2 establishes ROI among a set of partners able and willing to move quickly (the early adopters of the network). These initial parties will also need to decide whether to tackle a greenfield use case for its ease of adoption or to remediate an existing data sharing problem as a path to more immediate cost savings but potentially with higher total replacement costs.
- Phase 3: Filling out the spokes and expanding use cases – Phase 3 generally involves two dimensions of expansion. From the data network’s perspective, more partners are being added, continuously improving the overall accuracy and timeliness of information sharing as more data sources and sinks join the automated network. As larger and larger percentages of shared data become automated and trustworthy, individual company and aggregate costs and inefficiencies are lowered. In addition, the data model is often simultaneously being expanded to accommodate more use cases and additional workflows closely aligned with the network’s goals as a whole.
- Phase 4: Spokes-to-(new)-hubs – Phase 4 involves one or more parties starting to create new hubs of their own. This happens as they come to rely on the data platform as an essential element of their operational and/or analytic data strategy. Expanding their data networks upstream (towards, say, suppliers), downstream (into logistics), or sideways (through financial or other service providers) allows them to continue lowering costs and optimizing their business outcomes.
Achieving business leverage in a rapidly changing data environment
Line of business owners and IT leaders are strapped for staff and money, so solutions that leverage other investments or lower total spending are paramount. Because data sharing is critical to a company’s outcomes, it shouldn’t be postponed or traded off. After all, supplies have to arrive, finished goods have to reach customers, and financial records must be accurate and up to date.
Companies can realize value — and lower costs — by aligning data sharing network development with other key investments and approaches, most of which are already in flight.
Here’s a list of the top five initiatives for aligning on data network development:
1. Public cloud migration – Using public cloud compute and storage, even when motivated for other reasons, creates data co-locality and offers access to “big pipes” (private, high-speed, and so-called “dark networks”) operated by AWS, Google, and Microsoft.
Eliminating on-premise deployments simultaneously eliminates the network and data locality sharing obstacles those on-prem data centers created and simplifies the task of creating “data conduits” among network partners.
2. Database migration – Migrating to cloud databases and cloud file storage solutions has the additional payoff that data sharing generally becomes easier at the same time. Managed extract-transform-load (ETL) applications and services, public cloud sharing mechanisms, and the emerging data platform supercloud providers all target public cloud storage.
Getting data into a cloud storage solution often makes it “one click away” from easy sharing with partners.
3. Data lakes and “Zero ETL” solutions – Data warehouses and data lakes are well established, but what’s only now emerging is the high, ongoing cost companies are paying to feed these lakes with operational data. The category of “Zero ETL” solutions is emerging as a way to avoid the high development, operational, and staffing costs associated with bridging a company’s operational and analytics data solutions.
Real-time data platforms such as Vendia Share can play a key role here by eliminating the need for a separate ETL solution altogether, effectively gluing together operational data with an analytics platform such as Snowflake.
4. Nurturing data partnerships – Cross-company relationships that ingress or egress mission-critical data need to be nurtured at both business and technical levels. Challenges such as common data models, data cleansing and integrity constraints, and other details need to be worked out early and often.
Tasking executives and creating accountability for identifying, promoting, and maintaining data partnerships is a key element of a successful data network.
5. Data network platform providers – Vendor selection is critical. Details like SaaS versus self-hosted can mean the difference between millions of dollars in upfront infrastructure and development spending versus getting started immediately on a solution.
Critical questions to ask include whether multi-cloud is a feature or a DIY challenge left to the customer, how cross-party modeling and governance are handled, and whether APIs are generated automatically from a customer- or industry-specific data model versus being left as an (expensive) afterthought.
Data networks deliver competitive advantages
Business partnerships have always been essential in a company’s health and growth, but data networks have emerged as a key aspect of success for companies of all sizes. By focusing on the mission-critical data needed to power operations, customer outcomes, and decision-making, companies can ensure that they stay competitive and operate cost-effectively, even in challenging macroeconomic conditions.
Both analytics and real-time data platforms enable companies to invest in hub-and-spoke networks that reflect their need for business solutions like sharing key supplier, delivery, financial, manufacturing, and other data as if it were a single source of truth. Newer technologies delivered as SaaS platforms, in conjunction with public cloud migration, remove the conventional challenges that stood in the way of these outcomes.
By investing in a data sharing network, both central IT and lines of business can achieve better solutions faster and at lower costs. Forever.
Evaluate your data network needs and solutions
Want advice on how to (re)invest in your data sharing network? Ask our team how to quickly build trusted data networks across clouds, companies, regions, accounts, data warehouses, applications, and more.