


A data ecosystem is a network of connected data sources, applications, and tools that make it possible for organizations to collect, analyze, and share data. While once upon a time, data ecosystems lived within an organization’s four walls, today, they live across multiple organizations, industries, clouds, and governance models. Crossing these “canyons” is key to implementing an effective data strategy.
In this post, we will discuss what a data ecosystem is, some primary use cases, and the elements of an effective data ecosystem. Plus, we’ll help you rethink what’s possible for your organization and the partners you share data with as you collaborate in a trusted data platform — no matter what clouds or technological canyons you have to cross. After all, every organization needs to think of its data ecosystem as the pumping heart within its operational data strategy and a beautiful mind that makes it possible to unlock new business value for every party networked within the system.
What is a data ecosystem?
A data ecosystem consists of three key components: the people who use it, the technology that supports it, and the processes that facilitate it. The more a data ecosystem can give its users current, trusted data they need to inform thoughtful decisions and guide intelligent action, the more valuable it becomes.
For a data ecosystem to be valuable, it must
- Overcome manual reconciliation costs and risks with automation
- Operate with built-in privacy, governance, and access control
- Deliver truth-as-a-service with data that’s instantly up-to-date, tamperproof, traceable, and indisputable
In the worst case scenario, data really is everywhere. It’s in systems you don’t know about or can’t access. It’s in places your partners shouldn’t see (and vice versa). Its provenance is untraceable and inaudible. It’s unreconciled from multiple sources or out of date (“probably-maybe-I dunno, is it?”). In the best data ecosystems, well, we’re just not there yet.
Elements of a data ecosystem
There are several key elements that make up an effective data ecosystem.
- Connectivity and fault tolerance – Establishing and maintaining secure connections with high fault tolerance and low latency between all components and partner systems across your data ecosystem is foundational. If users cannot instantly access all relevant datasets within the data ecosystem, you’re burning resources.
- Scalability – Your system must scale up or down based on changing demands, partner agreements, and business opportunities. Your system must also scale for availability and stability. Too often, IT leaders try to solve this with DIY solutions, which turn into too much overhead capacity, wasted resources, and burned out developers.
- Automation – Automating certain processes within your data ecosystem reduces risks, cuts cost centers, and speeds up processes without sacrificing accuracy or quality in results. It also frees up talent for more important and professionally rewarding tasks that truly benefit from human intervention.
- Performance monitoring – This is another element that too many IT teams throw a lot of time at and only deliver middling dashboards with questionable data. But monitoring and measuring data ecosystem elements (including the others in this list) helps identify potential and emerging issues early on.
- Security – Allowing only authenticated users access into your system, and operating with fine-grained controls, helps ensure sensitive information remains private and confidential. It also supports data traceability and lineage integrity. Utilizing strong encryption protocols further bolsters security measures within the system.
- Governance and compliance – Establishing governance policies helps ensure organizational compliance with applicable laws and industry regulations. But policies aren’t going to keep you out of trouble. Applying these policies without fail across all components within your system helps always maintain trust with regulators, users, and customers who rely on you for quality services.
Examples and use cases for effective data ecosystems
Every organization in every industry will benefit from an effective data ecosystem. The enterprises that win first, win big, and continue to lead as innovators in their industry have made long-term investments in their data strategy. The path forward includes investing in partner data ecosystems and compliant, controlled data alliances that deliver superior customer experiences and business results.
Here are a few use cases for data ecosystems:
- Analytics – Data ecosystems provide organizations with valuable insights into their supply chain partners, customers, and market conditions. Consider semiconductor and chip manufacturing or automotive supply chains (Figure 1). Companies with end-to-end supply chain visibility layered with customer behavior data and market trends can make better strategic and tactical decisions about allocating resources, structuring their operations, managing waste, and improving their environmental impact.
- Marketing – When marketers can “stop admiring their data and start using it,” brands can create personalized marketing campaigns and compelling sales offers that target specific customer segments more effectively than ever before. With higher conversion rates and more significant ROI also comes the potential for richer customer experiences that build brand equity and shareholder value and increase the value of a customer for life.
- Operations – Look at the financial services industry, notably a mortgage-servicing use case. Lenders and their partners in loan servicing, loan packaging, and payment processing are already using new technology to automate manual reconciliation, reduce errors, and speed up transaction time. For the first time, it’s possible for every party involved to have tamperproof records of every transaction and know the status of every transaction to which it has access within seconds of it taking place — no matter which party the transaction initiates with.
FIGURE 1: An example of a supply chain ecosystem

How do you build a real-time data ecosystem across clouds and organizations?
Suppose you can build and operate in a data ecosystem that collects, stores, manages, and analyzes multi-partner data effectively. In that case, your organization will have wings made of much sturdier stuff than wax and feathers. But to create that, there are some essential steps to follow.
Step 1: Identify data types, locations, and standards, so your data ecosystem is clean and healthy
To better understand what kind of infrastructure and architecture you need to support your system and how to best organize it, you need to know what data you have, where it sits or comes from, and what your standards are for input, identification, validation, and use.
Here are some examples:
- What type of customer information do you have?
- How about sales numbers?
- What about product feedback?
- Is the data found all in one place (like a data lake or data warehouse) or spread across multiple databases, regions, organizations, or clouds?
- Is the data up-to-date?
- Is the data source trusted?
- What are the data governance considerations in your industry or geography?
- What’s your organizational code of ethics for handling data (or what do you want it to be going forward)?
♟️Potential challenges with identifying data types and locations
If your organization has been collecting large amounts of data over time without consistent attention to where it is stored or how it is organized, this step can be especially challenging (and you are not alone). Also, suppose certain types of data are not collected but should be included in the system. In that case, this step will require additional effort for sourcing, cleansing, and collecting those bits of information.
Step 2: Choose technologies to enable data tracking, storage, and transfer so your data ecosystem hums
Once you’ve identified the types and locations of data within your organization, it’s time to select the technology that not only make it possible to enable tracking, storage, and transfer within your system — you want to build a tech stack that makes it easy to build, manage, govern, and scale without sacrificing quality, insight access, and compliance.
From your data sources like an ERP, CRM, or OLTP (or spreadsheets?) all the way through the ecosystem “food chain” across to data reporting and visualizations a la Tableau, there are so many choices and configurations. Meanwhile, even with the best technology, organizations struggle to ensure data accuracy, uniformity, and timeliness. There is no golden record, or at least not one that leaders can trust.
♟️Potential challenges with choosing the right technology for your data ecosystem
In most enterprise use cases, choosing and integrating technology can take a lot of time and money. DIY solutions rarely perform as envisioned. Stack and infrastructure costs weigh on the budget, and opportunity costs continue to pile up (as does the wear and tear on your talent pool). The job gets even harder with you’re solving for a data ecosystem with multiple data sharing parties across regions and clouds. It gets harder still when you want or need to keep scaling up.
Most technological solutions still fall short:
- Data management platforms are not real-time
- Cloud service providers strategically avoid cross-cloud solutions
- Many private blockchains typically do not scale
- While public blockchains scale very well, they’re incredibly slow and cost inefficient
- API platforms aren’t smart; they’re ignorant pipes lending braun without brains
- Building and maintaining APIs for partner integrations require high effort
- Traditional ERPs are not SaaS or shareable
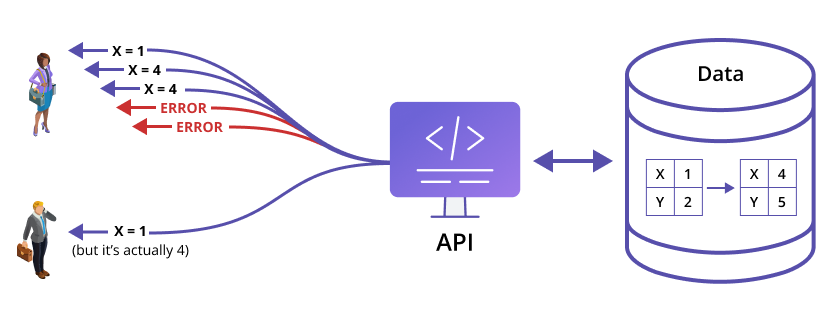
FIGURE 2: Traditional APIs can’t keep data consistent, at all times, everywhere the data lives. Polling too quickly keeps data up to date, but it leads to operational problems and high costs. Polling too slowly leads to data that exists as out-of-date copies of “the real data.”
Step 3: Create a system or process for analyzing data so you get the data you want and can trust
Once all relevant pieces of information have been collected and reconciled, it’s time to create a system or process for analyzing them. This process is either performed manually or automated using algorithms and machine learning (ML) techniques. No matter the approach, the goal is to extract meaningful insights as instantly as possible.
♟️Potential challenges in creating a system for data analysis
Analyzing large amounts of data (especially unstructured data or data you cannot trust to be real or up-to-date) can be hard. First, the team member or algorithm performing the analysis can be biased or make incorrect assumptions about how certain pieces fit together.
And even if every analyst and their technology shake out smart and useful insights all the time (which we know doesn’t happen, we’re human), having trained personnel analyze large sets manually is expensive (and stressful for employees). Organizations and teams benefit when there is balance between rewarding manual labor and efficient automation.
Step 4: Define the data outputs so you can leverage them quickly and with confidence
The goal for your data outputs is to have trusted business intelligence and business analytics at your fingertips, fast, so you can use them to make a business case, improve customer satisfaction scores, reduce your carbon footprint, get end-to-end supply chain visibility, and inform all kinds of both tactical and strategic business decisions.
- How can you best leverage your real-time operational data in the data ecosystem?
- What do you want your data to do for you as an analyst or line of business owner?
- What do you want your analytical data to look like (e.g., in a dashboard), generate (e.g., new data sets), or transform into (e.g., customer insights)?
- When it comes to partner data sharing, how will you access, transform, or deliver shared data outputs?
- What format do you want inputs from partners in your data ecosystem, and how do you need to transform them for your analysis or activation?
♟️Potential challenges in defining (and leveraging) data outputs
Your outputs are only as good as the quality of your inputs and your data architecture and solution patterns.
And they’re only useful if you can trust them; prove to other colleagues, partners, or regulators they’re trustworthy; and access them when you want and need them. It can also be challenging to manage the teams who reconcile your data outputs or build/integrate the software and dashboards you need. And, not for nothing, without the right controls on data outputs, you can expose customers and your organization to risk.
Step 5: Train departments or functions that interact with the data ecosystem so you make the most of what you have
Your team created the data ecosystem (or selected a valuable platform), and maybe you’ve even successfully onboarded partners into your data sharing network. Now you need to ensure it continues to work as intended, without failures in data accuracy, integrity, uniformity, timeliness, governance standards, or security measures. Teams must be onboarded and developed to use data, the systems, and its outputs effectively. This includes being heads up as troubleshooting partners as much as it does being advocates for future improvements and innovations. Every solution has a shelf life.
♟️Potential challenges in training and maintaining a data ecosystem
Headcount is expensive. Opportunity costs are a death by 1,000 cuts. And mistakes that lead to bad decisions or non-compliant data handling can be even more costly to your short-term bottom line and your long-term brand reputation.
Plus, if you haven’t been able to establish and ensure trust in your process and data, the challenges your team faces while defending it can weigh on employee satisfaction and personal health. So, if your system isn’t built effectively, or your team isn’t well-trained in using it, your organization may be caught in a cycle of human interventions and error-prone manual processes. And that’s just on the front end of using your data ecosystem. The maintenance on your backend software brings its own set of costs, risks, and challenges.
How Vendia can help you operate with speed and confidence in a real-time data ecosystem
Our team of solutions architects can help you eliminate cost and accelerate innovation by integrating Vendia’s trusted data cloud into your existing data ecosystem.
Our Serverless platform, Vendia Share, combines the best of API, distributed ledger, and database technology, so you can build an automated data ecosystem that’s always up-to-date and empowers all parties with a single source of truth.
Ask us for more information, sign up for the app to explore the platform’s building blocks, or ask us to build you a proof of concept in five business days.