

Background
Domain Driven Design (DDD) is the basis for decomposing monolithic applications into collaborating (micro, in many cases) services. The approach gained in popularity because it addressed some of the long-standing challenges of large, complex, monolithic operational applications. Benefits of a microservices approach included:
- Agility and Autonomy – Teams empowered to pursue business priorities with minimal cross-team touchpoints
- Technology Flexibility – Teams enabled to select the best technology for a given problem space, without impacting other teams
- Operational Ownership – Teams responsible for owning and operating the services, with the freedom to deploy small changes frequently
- Better, More Resilient Applications – Teams able to support real business needs more consistently, reliably, and effectively, and with the additional benefit of better application resilience
The same fundamental challenges that made teams rethink the best way to build and operate monolithic operational applications are forcing teams to reconsider how to build and operate analytic applications. Thankfully, the same DDD fundamentals that inspired microservices can be applied to monolithic analytic applications as well.
A Data Mesh rethinks modern enterprise data architecture – typically one where a centralized, monolithic Data Lake was prominently featured – and favors a composition of decentralized, collaborating data producers and consumers. A Data Mesh is important because it:
- Restructures enterprise data platform architectures around domains, following guidance from DDD
- Makes data products a top-priority output from each team and each domain, allowing other domains and other teams to use those data products as they see fit
Problems a data mesh addresses
The Data Mesh concept was created to directly address many of the challenges organizations faced after modernizing their enterprise data architecture around a Data Lake (or some variant thereof). These challenges included:
- Centralized and Specialized – A specialized, dedicated, and ever-growing team that was solely responsible for escorting source data through the lake, and making that data accessible to all types of disparate consumers
- Technology Stagnation – A centralized technology stack that was difficult to modify once entrenched, with existing product inertia growing over time
- Single Point of Failure – A large, bloated data hub that, when impacted, was felt across departments and businesses units; the risk potential further inhibited technical experimentation (e.g. afraid to break the monolith)
- Slow Outcomes, Outsized Investment – A centralized team, stuck with technology choices from years prior, with a large backlog of work from across the enterprise; getting data into the lake takes time, getting insights out of the lake requires close coordination with the already-overloaded centralized team
For those who’ve gone through the monolith to microservices decomposition for operational systems, the points above likely sound familiar. For those who are now working in a monolithic, “data lake-centric” environment for analytical systems, the points above likely also sound familiar. No matter your background, if the challenges above ring true, a data mesh architecture can certainly help.
You will likely see:
- Value in moving data ownership back to the domain from which it originates – with the lines blurring between operational and analytical data, the domain boundary (not the data processing stage boundary) is where there’s most value in developing specialization; cross-functional teams can work from the same, trusted set of data (e.g. accurate customer lists) and look for optimizations to streamline the operational-to-analytical data flows
- Value in decomposing a centralized, monolithic enterprise data architecture into a decentralized collection of data services – with autonomous teams responsible for producing data for others (in an open, agreed upon fashion) and responsible for consuming data from others (as they see fit)
- Value in enabling heterogeneous tooling to achieve business outcomes – with the onslaught of tooling available, the most differentiating solution is likely to span products, companies, and clouds
Not every company experiences the challenges above to the same degree. Likewise, not every company will see the same value for their investment in creating a decentralized data mesh. In either case, there are persistent enterprise data challenges that are not intended to be addressed by a data mesh. Solving for those persistent challenges, with an eye toward integrating with and enabling a data mesh in turn, is where we’ll focus next.
Persistent data challenges, even with a data mesh
Let’s assume adopting a data mesh architecture solves all the challenges of its centralized, monolithic predecessor (I’m optimistic). There are still some additional enterprise data challenges that a.) will make creating an ideal data mesh more challenging, time consuming, and expensive b.) can be solved, and solved well, using the same fundamentals that support a decentralized data mesh architecture.
Problems a data mesh will not solve
The problems outlined in this section are not deficiencies of a data mesh architecture. Instead, they demonstrate that a data mesh, with a focus on the analytical data plane of enterprise data architecture, places some additional expectations and responsibilities on the operational data plane. Specifically, the real-time operational source systems – and the real-time systems they interact with across organizational boundaries – should be constructed in such a way that makes integration with a data mesh simple, easy, and repeatable (thanks to common architectural patterns).
Engaging with real-time partner data
While quite a bit has been written about data meshes, much less is written about extending the boundaries of the mesh outside of a company’s four walls. There’s nothing inherent to a decentralized data mesh that would prevent it from spanning organizational boundaries, but doing so places some new requirements on operational systems. The value of producing data for partners and consuming data from partners is not a new or novel idea. The continued challenge is to do so effectively and in real-time, as if the data really was “shared” among partners and not a (batched) afterthought.
Improving control and trust across boundaries
Trust in data is equally important within and across organizational boundaries. Access controls must be in place to ensure continued partner participation and ensure unauthorized organizations and individuals are prevented from access they should not have. While access control has a foundational role in building trust within and across organizations, another important element is data quality. Partners gain trust in producing data for and consuming data from other partners when they have a shared, real-time understanding of syntax and semantics from the start.
Maintaining lineage inside and outside a company’s four walls
Another ingredient in the data trust equation, and one that ideally spans organizational boundaries, is data lineage. While a shared source of (current) truth is essential for real-time use cases – think autonomous, closed loop transactional workflows – having access to a full record of all transactions leading up to the current source truth can be extremely valuable. History provides context, context provides deeper understanding, and having that understanding in real-time is often critical to dynamic, autonomous decision making.
Improving your next-gen data mesh with real-time data sharing
To increase the value of a data mesh architecture and to address the persistent enterprise data architecture challenges outlined in the last section – challenges a data mesh was not intended to address – an additional capability is needed: a multi-party real-time data sharing solution. A real-time data sharing solution, like Vendia Share, fits squarely in the “operational systems” space, just to the left of source oriented domain data. Further, and to achieve real-time data sharing with multiple (writing) partners, to ensure trust in data access and data quality, and to provide transactional lineage across organizational boundaries, that real-time data sharing solution must inherently leverage a performant distributed ledger (e.g. an “enterprise” distributed ledger).
From Zhamak Dehghani‘s foundational post on the data mesh approach in 2019:
“The source domain datasets represent the facts and reality of the business. The source domain datasets capture the data that is mapped very closely to what the operational systems of their origin, systems of reality, generate…These facts are best known and generated by the operational systems that sit at the point of origin…The business facts are best presented as business Domain Events, can be stored and served as distributed logs of time-stamped events for any authorized consumer to access.”
With that understanding, it follows that a data mesh that incorporates operational data sourced from a real-time data sharing solution with distributed ledger properties may confer some advantages:
- A well constructed history of operational transactions, emitted as events from the source systems, bolsters the resilience of the source oriented domain data nodes in the data mesh
- A well constructed data mesh benefits from the access controls and shared data models put in place on the enterprise blockchain to make interorganizational data sharing ubiquitous
- A well constructed data mesh provides an optimal architecture to fully exploit shared partner data, provided that data is accessible, trustable, and timely to all domains in the data mesh.
So by combining an enterprise-grade distributed ledger (decentralized operational system) and a data mesh (decentralized source and consumer aligned domain datasets), you get the best of both worlds. Even better, there are patterns that apply Domain Driven Design techniques to a distributed ledger like Vendia Share.
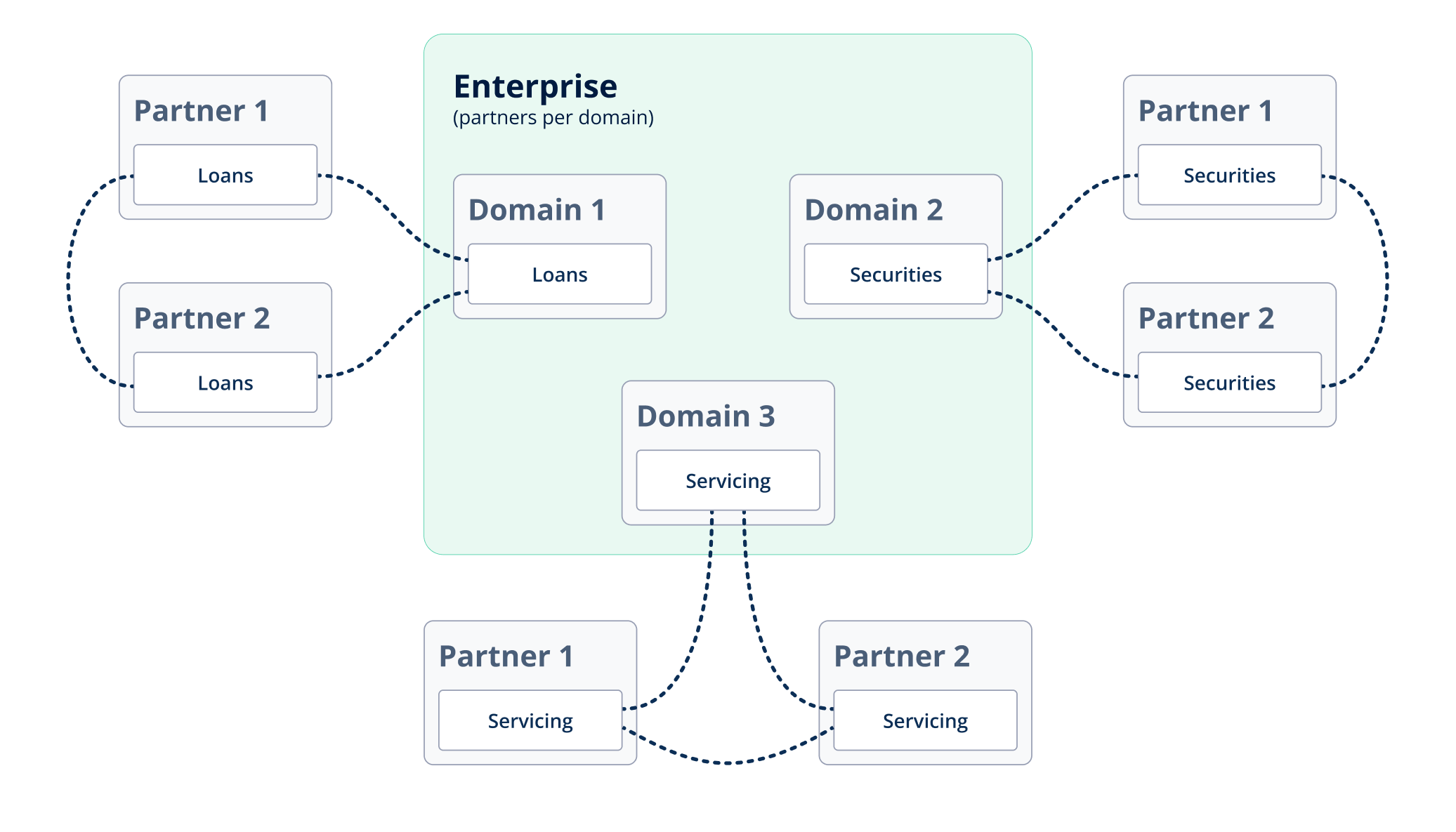
While I generally agree with Dehghani that, “the actual underlying storage [of source aligned domain datasets] must be suitable for big data, and separate from the existing operational databases”, a real-time data sharing solution like Vendia Share does account for some of the deficiencies seen by traditional, centralized, ledgerless databases. Vendia Share can handle a large number of transactions, large volumes of data, contains immutable timed facts, and can handle real-time data and data access changes. Exactly how far you can or should extend an enterprise distributed ledger into the source aligned domain dataset realm is a great topic for a future post.
For now, and to make the content a bit more tangible, let’s explore a real-world use case that hits close to home.
An Example: Homeowner payment assistance
This example explores how an enterprise distributed ledger combined with a data mesh allows a loan servicer to more effectively help a homeowner struggling to make monthly mortgage payments.
Participants
For simplicity, we’ll keep the number of participants involved to a minimum – just enough to show the intricacies of a real-world network for transacting partners.
- Home Owner – The person or people with a home loan; also known as the mortgagor
- Loan Owner – Either the original Lender, or the organization to which the Lender sold the home loan; also known as the mortgagee
- Loan Servicer – The organization servicing (e.g. collecting monthly payments and handling distributions) the home loan, and in many cases different from the Loan Owner
- Loan Securitizer – The organization that created a security from the home loan, possibly as a mortgage backed security
Context
In this scenario, a homeowner is unable to pay the expected amount by the expected data on their mortgage. The Loan Owner, Loan Servicer, and Loan Securitizer all have actions to take – some immediate (requiring transactional responses), some gradual (requiring analytical responses).
These include (and are a small subset of all possible actions):
- Loan Servicer Actions – Contacting the Home Owner to notify them of missed payment, determining likelihood of payment, and offering payment support options if the likelihood is not high
- Loan Owner Actions – Adjusting lending guidance based on historical, aggregated loan performance data, identifying payment trends that can be shared with originating Lenders
- Loan Securitizer Actions – Updating security disclosure calculations for all securities linked to the loan, dynamically adjusting market risk and exposure based on aggregated loan performance data
Challenges
The obstacles to handling the actions above effectively – consistently and in coordination with all impacted participants, including the Home Owner – are representative of the obstacles facing many multi-party business networks today:
- Participant Isolation – Ensuring the Loan Owner, Loan Servicer, and Loan Securitizer have a shared understanding is difficult. Each participant has its own copy of its own version of “loan data” – which is the most recent? the most accurate?
- Poor Data Input Quality and Timeliness – As soon as a payment is late, that information becomes incredibly important to all parties involved. Do the cross-organization data channels ensure timely delivery of the information and ensure the information is consistent across participants?
- Poor Data Output Quality and Timeliness – Once the missing payment information is received by each participant, they can each (concurrently) begin executing processes to address the late payment. Their responses can only be as good (e.g. individualized payment assistance plan options) and timely (e.g. within the current loan reporting period) as their prior investment in their (internal) enterprise data architecture.
- Lack of Historical Record – Accessing a complete historical record – spanning participant data systems – and maintaining the validity of the historical record – again spanning participant data systems – can be incredibly challenging. Knowing more about the Home Owner (e.g. credit score), the Loan Owner (e.g. overall loan portfolio health), the Loan Servicer (e.g. escrow withdraw timelines), and Loan Securitizer (e.g. bond ratings and compliance) would all be useful when optimizing a response plan to help the Home Owner.
Solutions
Let’s assume a best case scenario where a.) all participants have invested in a data mesh architecture to accelerate their in-house data process and resulting insights b.) all participants have built their operational systems on the Vendia Share platform to improve their ability to share data with each other in real time.
This solution directly addresses all the challenges above:
- Participant Connection – Information relevant to each participant is immediately available and consistent across all parties. Time is spent on payment remediation instead of on data reconciliation.
- High Data Input Quality and Timeliness – The shared ledger among participants allows operational data to be immediately available and highly trustworthy. The data mesh investment by all participants allows their respective data insights, recommendation models, and analytics processes to begin cranking immediately.
- High Data Output Quality and Timeliness – The data mesh investment by all participants allows for better quality results from their various processes. The iterative experimentation that’s resulted within each organization thanks to their data mesh adoption now pays dividends.
- Immutable Historical Record – The participants have the benefit of a more complete understanding of the loan and payment history that occurred prior to the late payment, and continue to grow that history with new information as they provide options for, and ultimately determine the outcome for, late payment remediation.
Benefits
The approach above has many benefits to the parties involved. And these benefits are analogous to the benefits seen by those adopting a data mesh architecture. This shouldn’t be surprising – pushing the boundaries of a data mesh beyond the boundaries of an organization’s four walls is a great application of an enterprise distributed ledger. This expansion should amplify the benefits of an organization’s data mesh investment, and possibly even streamline its creation of the datamesh to begin with.
- Trust in Data – Input data is more likely to be trusted because it came from a shared source of truth. Output data is more likely to be trusted because it was produced from trustworthy input data. The end-to-end process is more likely to be trusted because data lineage and data access controls can more easily span organizational boundaries. The continuity among participants can even be exposed to the Home Owner, who is more likely to gain trust in those attempting to help.
- Scale as an Enabler – The centralized monolith in enterprise data architecture falls apart at scale. Because a decentralized data mesh is built to scale, and because better insights and recommendations will come from scale, the Home Owner now benefits from the scale made possible (compare this experience to the opposite – the Home Owner struggling to work across disconnected participants, pushed beyond their ability to scale).
- Rapid Response Times – The Home Owner is able to get a personalized set of recommendations, delivered promptly, from all participants involved in real-time. Likewise, each participant is able to take action – either immediate or gradual – based on a current and accurate view of their (shared) world.
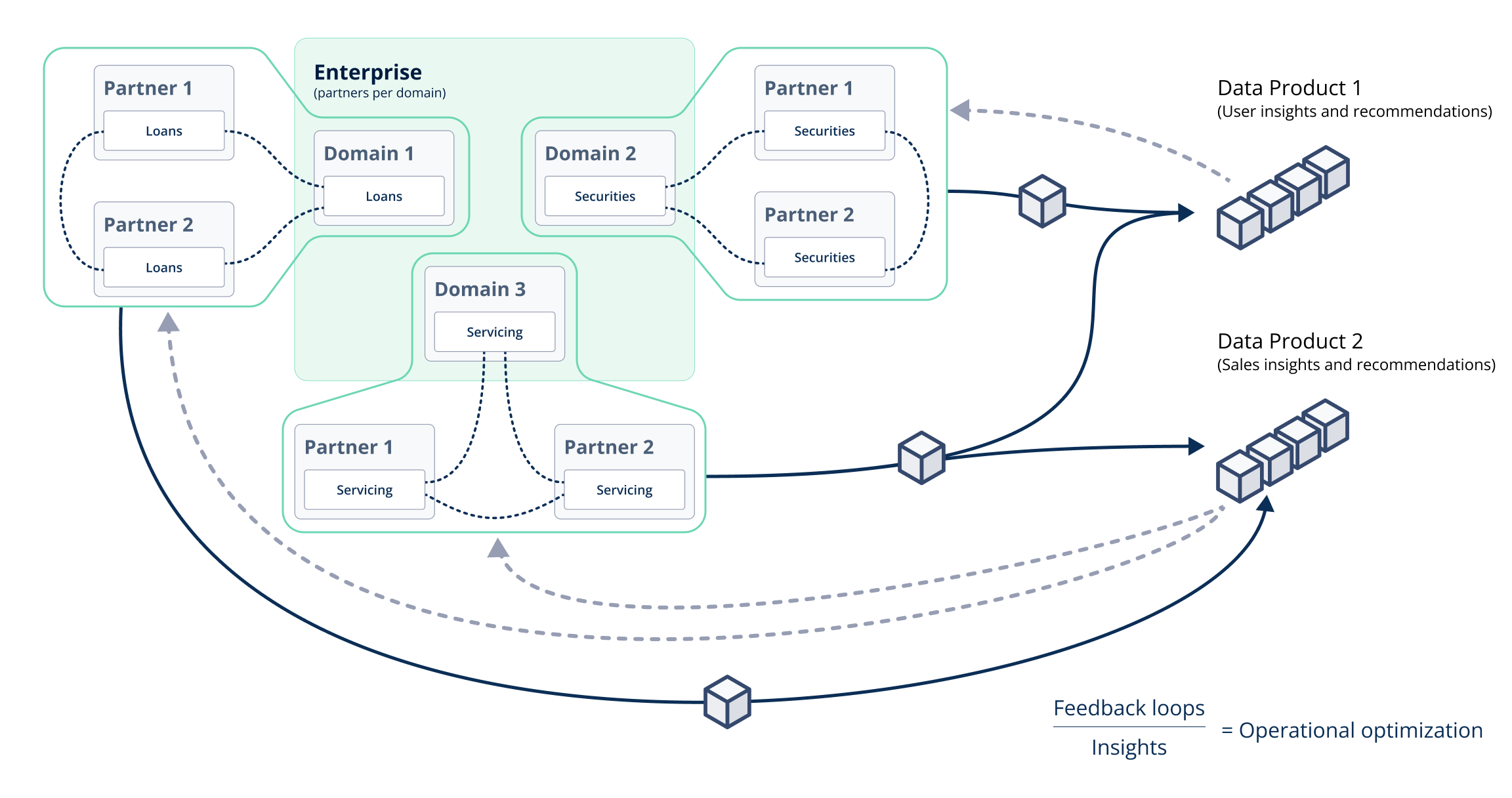
Closing thoughts
A data mesh architecture, heavily influenced by DDD, addresses many of the common challenges organizations face when their enterprise data architecture monoliths begin to impede team autonomy, technology experimentation, and the ability to quickly deliver new data offerings. The end result is fully aligned with DDD:
- Teams empowered to pursue business priorities with minimal touchpoints, across teams and organizations
- Teams enabled to select the best technology for a given problem space, without impacting other teams
- Teams responsible for owning and operating services, with the freedom to deploy small changes frequently
- Teams able to support real business needs more consistently, reliably, and effectively, and with the additional benefit of better application resilience
A real-time data sharing solution like Vendia Share helps organizations push the boundary, and impact, of their data mesh beyond their four walls. As seen in the Home Payment Assistance example, the combination provides many consumer benefits, as organizations can effectively share data with each other and effectively exploit the shared data to do what was previously not possible.
By integrating an enterprise distributed ledger like Vendia Share with their data mesh, organizations can streamline the development of their enterprise data architecture while also maximizing their investment by extracting value from data sourced from inside and outside their organization. Learn more about our solution.