


Most business-critical data now lives outside a company’s four walls, even while it remains very much inside the company’s legal, regulatory, and business responsibilities. As a result, the most important data infrastructure a company manages today isn’t server racks or even databases.
The most important data infrastructure a company manages is its business data network.
Business data networks through time
Data networks aren’t new. The Roman Empire (Figure 1) was coordinating far-flung supply chains with growing populations long before Charles Babbage and Ada Lovelace created the first computer.
Figure 1: Part of the Roman Empire’s supply chain, circa 146 B.C. – 439 A.D.
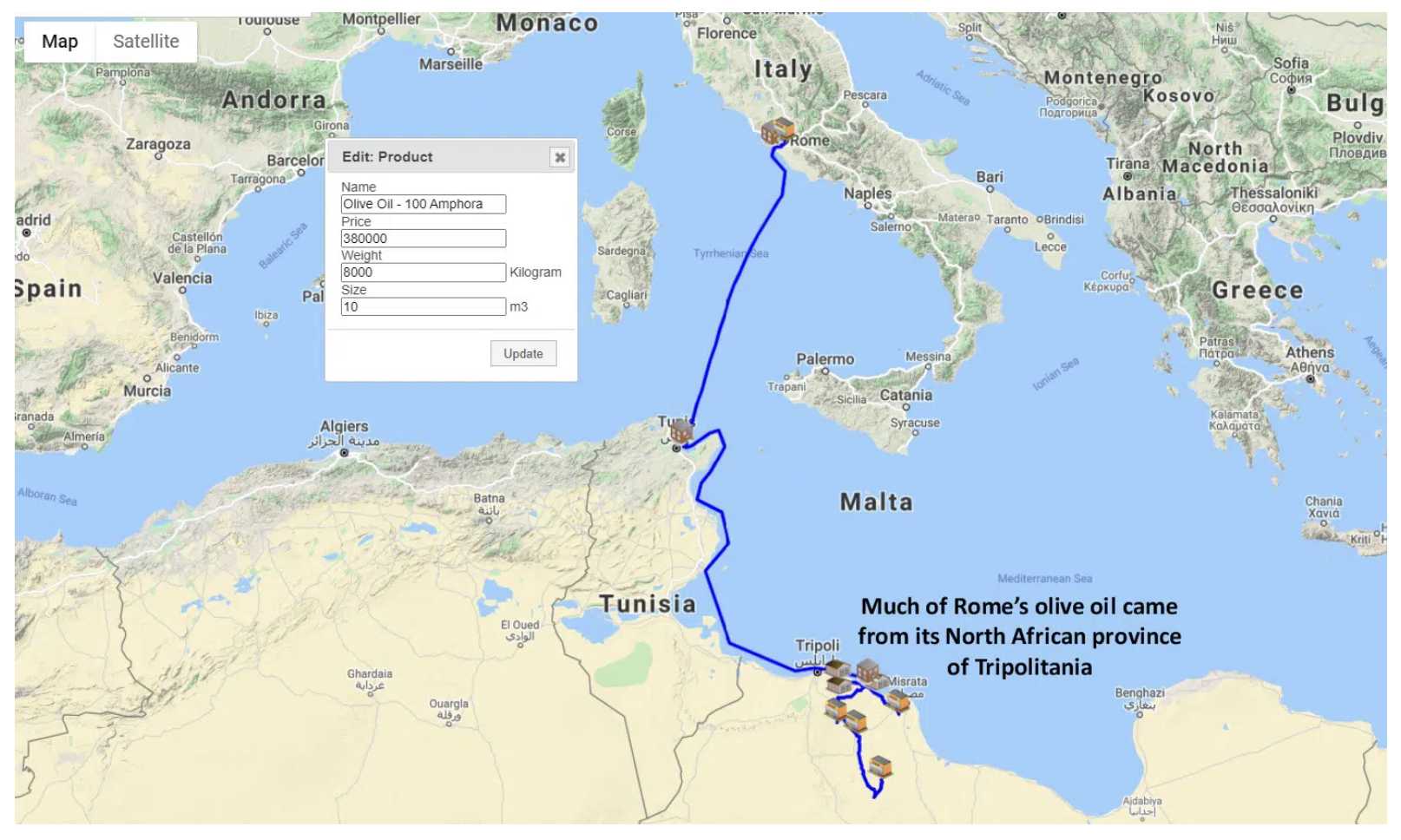
This supply chain moved olive oil, wheat, and dates from provinces in Roman North Africa (now Tunisia and Libya) across the Tyrrhenian Sea in the Mediterranean to supply the City of Rome (Image source: scmglobe.com)
But over the last 50 years, improvements in both communication and automation technologies have driven efficiency gains among partner data networks. Some of these foundational technologies are still in use today.
1. File transfer technologies – SFTP/MFT
Most business data sharing between companies (and often even within companies) still happens through files. While they lack many of the fine-grained capabilities of a database, files remain a critical piece of the data sharing puzzle. File sharings remains critical primarily because they are a dense, compartmentalized source and conduit of information. These characteristics enable files to easily transmit complex details — like a spreadsheet representing a company’s cash flow — in a single, simple, consistent package. Files facilitate human-to-machine communication. But they also work well for machine-to-machine workflows, where secure file transfer protocol (SFTP) and managed file transfer (MFT) remain important cornerstone technologies for intra- and inter-company data transfer despite the age of these approaches.
Most SFTP/MFT-based architectures are locked out of real-time data sharing.
However, the denseness of file content has a downside: it requires processing a lot of data, and most companies can only afford to share the files infrequently due to the time, people, and infrastructure costs associated with the “bulk” processing that follows. Turning a “once-a-day” file transfer and its accompanying workflows into a “10 times a second” mechanism is rarely possible, making file-based transfer a poor choice for any type of data powering web and mobile applications.
This gap leaves most SFTP/MFT-based architectures locked out of real-time data sharing. It also makes it difficult for companies dependent on files as a data sharing mechanism to respond to fast-changing conditions or deliver better customer experiences that require up-to-date or fully consistent information.
2. Business protocol connections – EDI and APIs
To get closer to exchanging real-time information, businesses also use APIs, with the EDI protocol being one of the oldest (it’s so old, it predates the Internet by decades). The premise behind EDI (and more modern B2B APIs) is to create a real-time conduit between businesses. Rather than relying on an overnight or periodic batch transfer based on files that could be out of date by the next day, EDI and API technology makes it possible to exchange information as it changes or when needed.
In addition to its aging protocol and format concerns, EDI shares a weakness with its more modern API counterparts.
EDI and API-based approaches leave companies continuously uncertain about the accuracy, provenance, and compliance of the data shared.
EDI focuses on the uninteresting problem of “moving bits” rather than the more important problem of keeping those bits of information consistent, correct, and up to date across the various data sharing partners.
For example, suppose a supplier is running low on inventory. In that case, it may tell one manufacturer that it has 10 units left. By the time that manufacturer does something with the information, the supply has dropped to 0 because another manufacturer took the remaining inventory.
With no way to keep data synchronized or auditable, EDI and API-based approaches leave companies continuously uncertain about the accuracy, provenance, and compliance of the data shared.
3. Manual approaches
It’s a mistake to assume that all inter-company data sharing lives under IT’s control. In fact, knowledge workers and other employees still share a surprisingly large percentage of mission-critical data using manual, ad-hoc mechanisms like email, Dropbox, Google Drive, OneDrive, etc. This is especially true for remediation and customer support teams tasked with resolving inconsistencies or missing information in shared data, such as accounting problems, inventory snafus, travel and loyalty program escalations, and more.
- In the absence of consistent and up-to-date data sharing, expensive and time-consuming manual “data fix-up” processes are often required.
- Unfortunately, manual data sharing and manual intervention often add to the problem with their inherent error rates and human toil-induced time delays.
- Manual data sharing outside IT’s purview is also a source of concern on other fronts, as it’s easy to evade corporate data sharing rules that can affect a company’s security, compliance stance, and audit results.
4. The public cloud
Before the public cloud, many data sharing problems focused on solving what was essentially a communication challenge — moving bits. Before ~2010, most corporate data was locked up in independently-owned, on-premise data centers.
The public cloud also had a powerful long-term impact that transcends operating margins — the co-locality of data and systems belonging to different companies.
The public cloud’s impact on data sharing
Getting data out of one company’s mainframes, servers, and databases and into another company’s mainframes, servers, and databases was, in and of itself, a huge (sometimes insurmountable) problem. The problem led to today’s corporate reliance on protocols like SFTP and EDI. Even when the data could be readily shared and used on both sides, building the bridge to convey it between two companies (let alone among dozens or hundreds of partners) was also often a huge IT project.
While much has been written about the public cloud’s economic advantages, it has also had a powerful long-term impact that transcends operating margins — the co-locality of data and systems belonging to different companies.
Suddenly, instead of two different databases in two different on-premise data centers managed by two different companies, enterprises found themselves residents in the same public cloud (typically AWS or Azure). Sometimes they even found themselves in the same region of the same cloud. In those cases, sharing data in a service (such as Amazon S3) became as simple as setting a line in a resource policy to add another company’s account number. What had been months of complex, multi-party IT labor was suddenly reduced to as little as a single line of IT configuration.
With the public cloud available, what had been months of complex, multi-party IT labor was suddenly reduced to as little as a single line of IT configuration.
Of course, not all data sharing is so simple, even in a cloud-powered environment.
Different clouds, services, and regions still represent “data canyons” that companies and their partners need to span. Meanwhile, real-world challenges like data transfer fees still get in the way of doing so easily and economically. But the public cloud (and the ever-improving Internet networking that enables it to exist) has been remarkably effective in lowering many communication barriers that once stood in the way of sharing data between partners. Lowering the barrier has allowed companies to focus on the next set of challenges — getting that data to be consistent, real-time, and auditable.
The future of data networks is the data supercloud Neither a single public cloud (nor a private cloud) can solve a company’s data sharing problems at large. These “walled gardens” simply don’t permit the kind of multi-cloud and partner-enabled sharing patterns that match modern corporate needs. Rather than trying to strand data beyond garden walls, successful data platform companies are making their offerings cloud-ready and building in multi-cloud sharing as a product feature. They may even, soon, be recognized as a legal entity, the Data Trust.
On the analytics data side, Snowflake is a great example. A company using Snowflake can share its data with a business partner regardless of what public cloud the partner happens to be on. AWS to Azure, Azure to GCP, GCP to AWS, it doesn’t matter. Instead of simply supporting deployments to different clouds (and making cross-cloud data sharing the customer’s problem to solve), Snowflake created a seamless, “virtual” data cloud that spans all the public clouds…and all their users. On the operational data side, companies like Vendia represent a similar approach for real-time and application data, providing a data platform that allows partners to share fine-grained information about supply chains, financial transactions, or other mission-critical processes regardless of who’s using which cloud provider.
These newer supercloud approaches to data, delivered as SaaS and serverless offerings, are designed to remove some of the key challenges facing IT:
- Zero footprint – There are no servers to purchase, rent, secure, scale, or manage
- Subscription– and usage-based – No CapEx expenditures and cost-following OpEx
- Deployment, integration, and multi-cloud “out of the box” – These capabilities don’t require months of analysis and an expensive IT lift; they’re ready to deliver (and proven out by other customers) on Day 0
Customers who choose these platforms can dramatically reduce both near-term and long-term IT investments by eliminating the undifferentiated heavy lifting required to build their own secure, compliant, cross-cloud data infrastructure. And then, they can immediately apply their cost savings to the business challenges they’re looking to solve with their partners or through the insights gained from a multi-party data exchange.
The future of data networks is the data supercloud
Neither a single public cloud (nor a private cloud) can solve a company’s data sharing problems at large. These “walled gardens” simply don’t permit the kind of multi-cloud and partner-enabled sharing patterns that match modern corporate needs. Rather than trying to strand data beyond garden walls, successful data platform companies are making their offerings cloud-ready and building in multi-cloud sharing as a product feature. They may even, soon, be recognized as a legal entity, the Data Trust.
- On the analytics data side, Snowflake is a great example. A company using Snowflake can share its data with a business partner regardless of what public cloud the partner happens to be on. AWS to Azure, Azure to GCP, GCP to AWS, it doesn’t matter. Instead of simply supporting deployments to different clouds (and making cross-cloud data sharing the customer’s problem to solve), Snowflake created a seamless, “virtual” data cloud that spans all the public clouds…and all their users.
- On the operational data side, companies like Vendia represent a similar approach for real-time and application data, providing a data platform that allows partners to share fine-grained information about supply chains, financial transactions, or other mission-critical processes regardless of who’s using which cloud provider.
These newer supercloud approaches to data, delivered as SaaS and serverless offerings, are designed to remove some of the key challenges facing IT:
- Zero footprint – There are no servers to purchase, rent, secure, scale, or manage
- Subscription- and usage-based – No CapEx expenditures and cost-following OpEx
- Deployment, integration, and multi-cloud “out of the box” – These capabilities don’t require months of analysis and an expensive IT lift; they’re ready to deliver (and proven out by other customers) on Day 0
Customers who choose these platforms can dramatically reduce both near-term and long-term IT investments by eliminating the undifferentiated heavy lifting required to build their own secure, compliant, cross-cloud data infrastructure. And then, they can immediately apply their cost savings to the business challenges they’re looking to solve with their partners or through the insights gained from a multi-party data exchange.
Supercloud data strategies delivered as SaaS and serverless platforms can dramatically reduce near- and long-term IT investments by eliminating the undifferentiated heavy lifting required to DIY secure, compliant, cross-cloud data infrastructure. Then, they offer cost savings business owners can apply to the challenges they’re looking to solve with their partners or through the insights gained from their new data trust.
Creating and operating modern business data networks
Any business partnership requires time, energy, people, and investment. It also needs a provable ROI to justify the initial and ongoing cost required to maintain and expand the data network.
What’s the underlying rationale for investing in a business data network, and what technical challenges can it eliminate?
Real-time systems – Data guaranteed to be up to date
Supplier inventory levels, flight delays or cancellations and the resulting travel plan changes, and financial market data are all examples of real-world, real-time data. For years, overnight file drops and batch processes have dominated the business-to-business data sharing workflows in these scenarios. But in an era where both executives and customers demand instant, up-to-date, and self-service information on desktop dashboards, business websites, and in their mobile apps, batch processing struggles to keep pace with customer expectations and business needs. Waiting to share such mission-critical data inevitably compromises its value and trustworthiness.
In an era where both executives and customers demand instant, up-to-date, and self-service information, batch processing struggles to keep pace with customer expectations and business needs. Delays in sharing such mission-critical data inevitably compromise its value and trustworthiness.
Single source of truth – Data guaranteed to be accurate
Closely related to the need for real-time data sharing is the importance of having a single source of truth across different parties. Consider a traveler trying to rebook air travel during inclement weather. Even if their current itinerary is available through an API, three different businesses calling that API at three different times might result in three completely different answers — and at least two answers are guaranteed to be wrong! Data networks based on an appropriate choice of data platforms don’t just ease integration concerns. They structurally address one of the most complex problems facing IT teams: keeping data consistent across partners, clouds, regions, and divisions.
All data trust partners can count on a shared, single source of truth and trust that the data powering their business decisions, operational processes, and customer experiences are indisputably correct.
A single source of truth among parties allows all network partners to operate without fear that the data powering their business decisions and customer or operational processes is fundamentally wrong.
Remediation-free workflows – Eliminating the high cost of being wrong
In the absence of real-time data sharing and a single source of truth, IT and operational managers have no choice but to staff complex responses to the very real possibility that their data is just fundamentally wrong. Teams focused on data remediation can take many forms, but their role is always similar. They exist to address the time lag of batch systems and the lack of a single source of truth inevitably causing problems, from irate travelers to a manufacturing line shut down because inventory isn’t available as expected. Data networks reduce or eliminate remediation staffing, infrastructure, and process costs by attacking the fundamental issue of outdated, incomplete, and untrustworthy business data in a company’s mission-critical systems and applications. Real-time data platforms upgrade EDI and API-based approaches, transforming them into trustworthy data sharing solutions.
Why data networks are good for business owners
Hint, hint. They deliver far better outcomes at much lower cost.
Data networks aren’t just technically and operationally savvy; they’re good for all the businesses involved. After all, slow, erratic, or costly data sharing mechanisms inhibit sales, add friction to customer experiences, and create or exacerbate security and compliance problems that could have been easily avoided. Building a strong and well-managed data network has multiple benefits, including addressing regulatory and customer concerns, offering cost savings, and delivering better customer experiences and service outcomes.
Addressing regulatory and customer concerns with data networks
For years, companies and their legal teams were okay with a “property line” argument when it came to sensitive data handling. As long as they kept their own IT infrastructure and staff in order, what happened elsewhere to customer data didn’t represent a legal or regulatory risk. But empowered by regulations like Europe’s GDPR and California’s CCPA and CPRA/Prop 24, individuals, public advocacy groups, regulatory agencies, and even other companies are increasingly holding enterprises accountable for any mishandling of sensitive customer or employee data — regardless of where it occurs or whose nominal fault it might have been.
How do data networks address regulatory and customer concerns?
Data networks offer a “better together” strategy. They enable the network — as a whole — to deliver guarantees about data privacy protection, customer-requested redaction or remediation, and joint governance and regulatory compliance. Those deliverables are automatically enforced by the platform and easily auditable by a third party.
Cost savings in automated data sharing networks
Inaccurate data isn’t only a legal and regulatory burden; it’s a bottom line issue, too. The costs required to detect and remediate data, especially when it requires manual communication and coordination with human counterparts in other companies, are extraordinarily high. Human-coordinated data exchange is as much as 100,000 times more expensive than machine-to-machine data transfer, to say nothing of the time required to detect, diagnose, and re-apply corrected data by both parties.
How do data networks lower business costs?
Data networks dramatically lower the cost of maintaining a complete, correct, and timely view of data that offers a single source of truth to all parties in the network. In short, trusted data is cheaper data.
Trusted data is cheaper data.
Better customer experiences and service outcomes
Long wait times rival unsolicited phone calls as the chief sources of customer dissatisfaction. Companies that still demand “4 to 6 weeks” for data to be exchanged or updated generally elicit derisive laughter more often than patient understanding from customers expecting loyalty programs, product deliveries, or other business outcomes to materialize.
How do data networks contribute to better customer service outcomes?
Data networks create controlled sharing and joint ownership alliances that help all the businesses involved serve customers better and become more competitive. For instance, reducing data synchronization to sub-second times enables interactive websites and mobile app experiences that customers enjoy and that exceptional customer service demands. Meanwhile, sharing marketing, sales, and customer information enables partners to expand both individual and shared business outcomes by better leveraging market opportunities in real time.
Data networks will deliver competitive advantages
Business partnerships have always been essential in a company’s health and growth, but data networks have emerged as a key aspect of success for companies of all sizes. By focusing on the mission-critical data needed to power operations, customer outcomes, and decision making, companies can ensure that they stay competitive and operate cost-effectively, even in challenging macroeconomic conditions.
By investing in a data sharing network, both central IT and lines of business can achieve better solutions faster and at lower costs. Forever.
Both analytics and real-time data platforms enable companies to invest in hub-and-spoke networks that reflect their need for business solutions like sharing key supplier, delivery, financial, manufacturing, and other data as if it were a single source of truth. Newer technologies delivered as SaaS platforms, in conjunction with public cloud migration, remove the conventional challenges that stood in the way of these outcomes. As a result, both central IT and lines of business can achieve solutions faster and at lower costs.
Evaluate your data network needs and solutions
Want advice on how to (re)invest in your data sharing network? Ask our team how to quickly build trusted data networks across clouds, companies, regions, accounts, data warehouses, applications, and more.
Or inquire about a free five-day proof of concept to see what’s possible for your organization — in record time.