

Like landscapes made of LEGOs, Magna Tiles, and K’nex (not to mention legacy systems like Lincoln Logs), the ever-growing list of data tools are fantastic resources…until you try to integrate them into a unified, simple data ecosystem.
Connecting this veritable slew of tools into a trusted, unified view is overwhelmingly complex (Figure 1), especially when you want performant, efficient, scalable, compliant, and secure service. And that’s just inside one company’s four walls. Sharing data with our partners, meaning companies outside our four walls in a lush data landscape, is even more complex.
Figure 1: Connecting this veritable slew of tools into a trusted, unified view is overwhelmingly complex
What is data sharing, and why do we do it?
Data sharing is the ability to send information, or data, back and forth within your business network’s (or partners’) respective environments. Commonly, data sharing is focused on augmenting analytical data for data-driven insights. Historically, analytics teams used data only available within a company’s four walls; this limited the capability for insights because it didn’t include all the data needed to make the best business decisions.
For example, desirable external data might include industry-agnostic data like financial stock trends, census data, and weather history or predictions. It might also include industry- and partner-specific data like farm locations and certifications, fabless facility uptime or material costs, automotive part availability, or sensitive healthcare and pharmaceutical research results.
Data consumers vs. data producers
What tool is great for data sharing? Snowflake, of course. Building out data consolidation efforts on Snowflake lets you easily harness that already consolidated data and saddle it for sharing purposes.
- With Snowflake, you can easily share data with partners already within the Snowflake ecosystem, making data available within their respective Snowflake accounts.
- You can consolidate and maintain control of the state of data by delineating data producers (your teams) from data consumers (your partners with read-only access).
- In turn, you encourage consolidating data driven-workloads to occur directly on that data or shared data within Snowflake for your analytical processes.
Still, in this context, even when you’re sharing data with an external partner who uses Snowflake, the person, team, or parties outside your four walls, the partner is relegated to data consumer status. They receive the data, but they can only consume it by looking at it, and they can’t make direct changes, update information or add any more to the data set. Snowflake is a one-way delivery system.
Why would an organization want two-way data collaboration? Some data producers need to simultaneously be consumers and vice versa.
Examples of data producers vs. data consumers
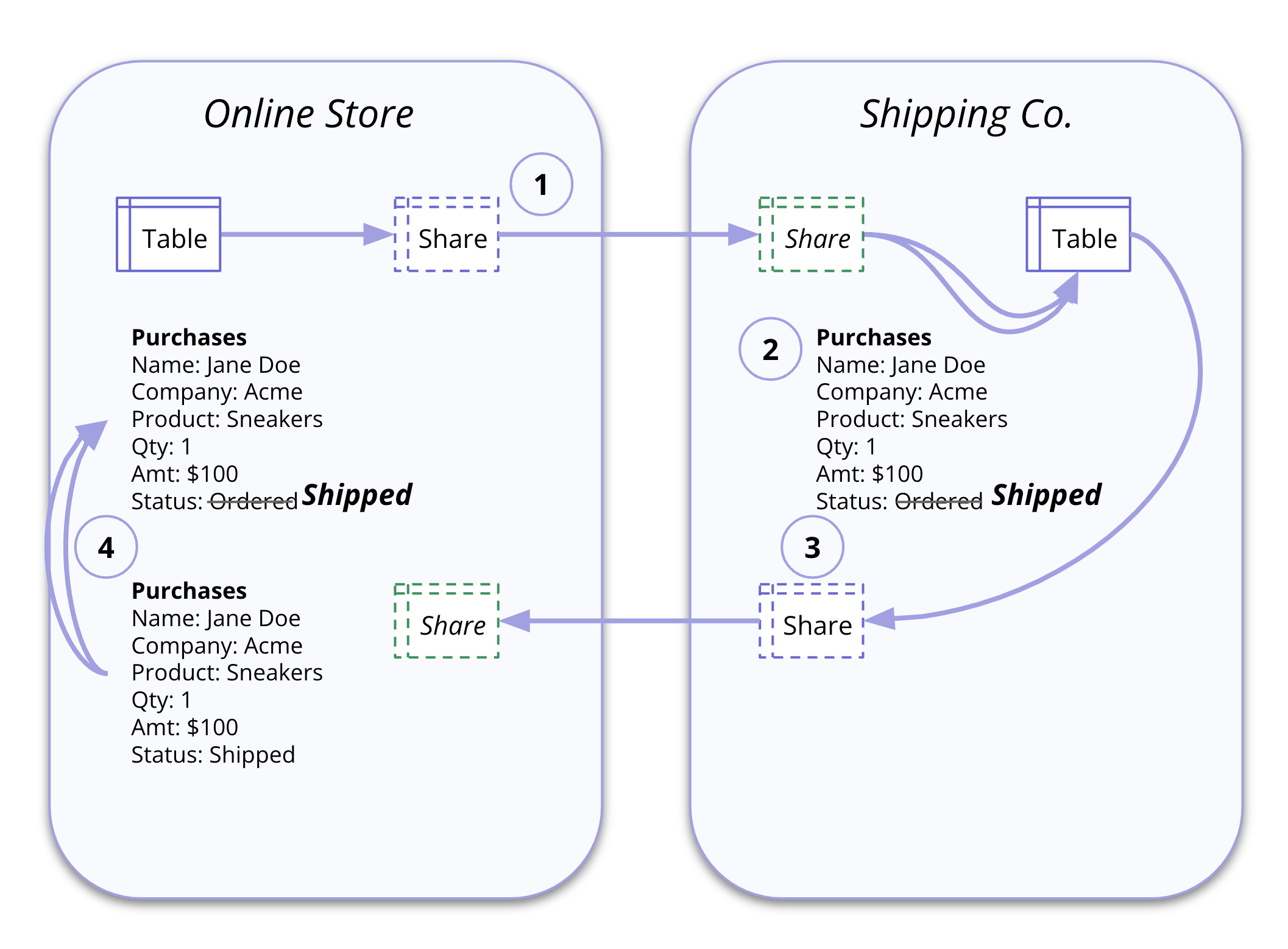
Let’s make it real. Let’s delineate an online store as the data producer and a shipping company as a data partner and data consumer. Step-by-step, here’s how data collaboration would be realized in a data sharing solution (Figure 2).
- The online store is a data producer because it receives a purchase request made by Jane Doe for some sneakers. This is written to their main purchases table; the online store creates a data sharing moment to provide that purchase information to their partner, the shipping company.
- The shipping company acts as both a data consumer and a producer. As a consumer, they received the latest purchase order. They then copy and edit the data as they execute Jane’s sneaker order.
- As data producers, the shipping company copies or integrates that data into one of their tables to update the status to “shipped.” But they also want to share this new status back to the online store so the shopper can see the “shipped” status. To make it work, the shipping company must now reshare that data back to the online store in a parallel but separate sharing path.
- The online store becomes the data consumer. The online store must merge that new data back into the original table. And to do this, they must use ETL pipelines and deduplication logic and versioning to ensure they have the most up-to-date order status.
Figure 2: Data sharing and collaboration in a two-party ecosystem
While this is cumbersome, it’s not painfully inefficient with two partners. Especially since organizations are used to this process. We’ve stewed in it for a while, and it feels normal.
But let’s expand this scenario into a multi-party data sharing network with a broader set of partners:
- Another storefront that also sells products
- Another shipping company for distribution in another part of the country
- A marketing agency that helps advertise our product
- A supplier that makes the product and manages inventory
This other storefront selling the product must receive the shared data from the shipping company and also integrate the latest status into their dataset. If they want to collaborate with the shipping company, the storefront must then separately share that data with the shipping company. And the shipping company must integrate that new information into their tables.
If the online store partners with another shipping company, they must also receive that shared data and copy and integrate those purchases into their data set.
For the online store to get the latest shipping status, the other shipping company must share that data back, which must be integrated into the online store’s table through logic or ETL processes.
That same back-and-forth with parallel sharing paths and data integration must occur with that marketing agency to receive purchase information and send over insights. And then again with the product supplier that needs to update their inventory based on shopping updates.
Figure 3: Data sharing and collaboration in a messy multi-partner ecosystem
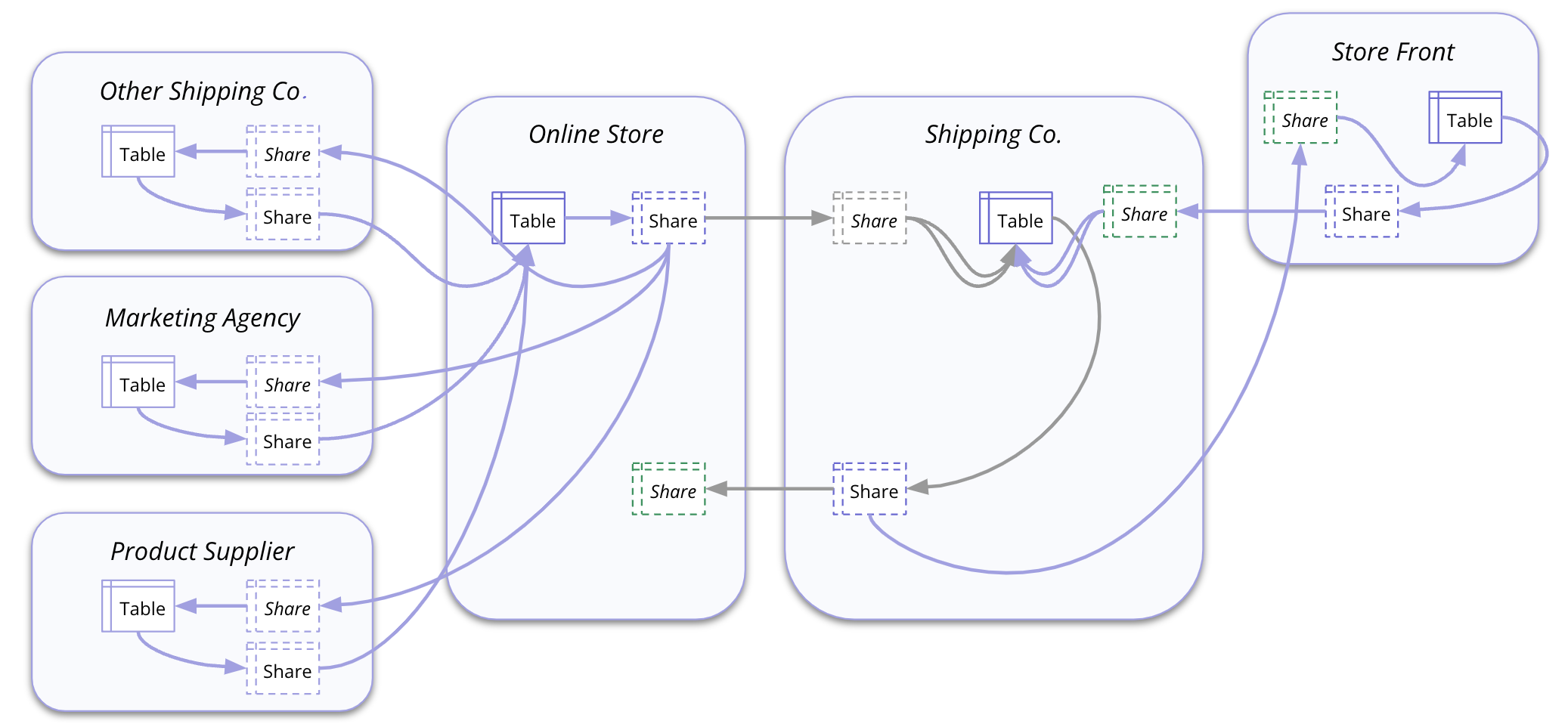
Things just got really messy really fast
Data sharing, merging, and deduplication are needed to consolidate and reconcile the various updates across all parties involved. And each new share, consolidation, and reconciliation requires new code to manage and merge these updates.
Again, the process isn’t complex with two parties. Data sharing is a great solution for that read-only distribution model. But when we have three, four, or more parties (which is the reality in our global marketplace), data sharing becomes…unwieldy.
For data collaboration, we need to add a new tool to our data landscapes
Let’s start fresh and imagine that same multi-partner business network using a data collaboration solution like Vendia Share with Snowflake.
- We have our handy dandy online store and all the partners around them. And the online store has that same purchase and now inventory data.
- Once it’s entered into their data set, it’s immediately shared (real real-time data sharing) with every partner in their network.
- Some of the information is redacted from certain partners:
- The shipping companies and marketing agency don’t receive the product amount data.
- The marketing agency doesn’t receive the name as its PII or shipping status.
- The product supplier receives only the inventory data.
- And that storefront doesn’t need any data from the online store.
All of these permissions and views or redactions are immediately applied upon creating the purchase and inventory data. And now the fun part…the multi-directional updates (Figure 4).
Figure 4: With Vendia Share, data is shared with control and compliance for real-time actions
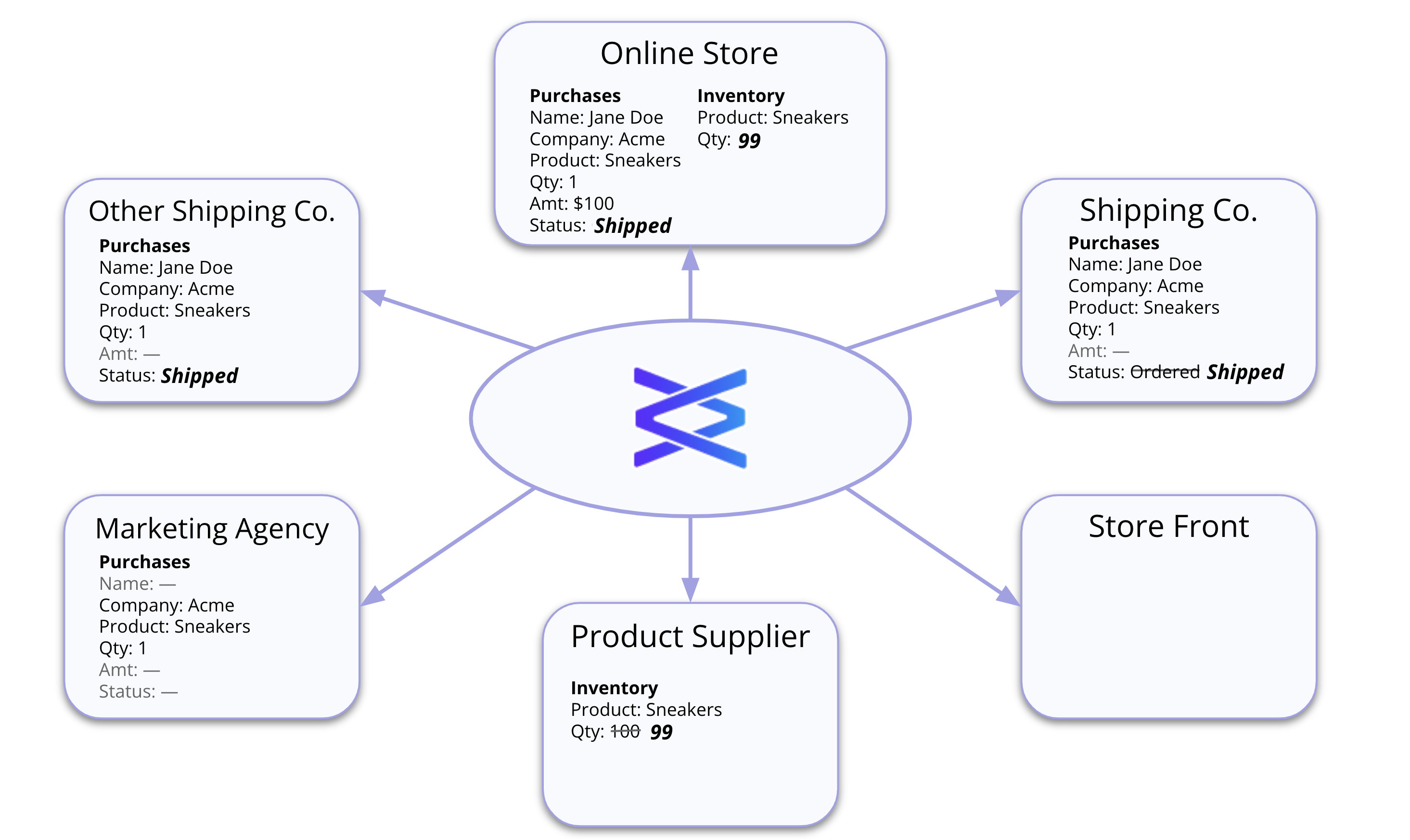
- The shipping company updates its data directly to set the shipping status without requiring any copies.
- That information is updated in real time in each partner’s respective data set, providing them with real-time information on the latest status as it’s made.
- Similarly, the product supplier updates the inventory.
- And the online store immediately receives that latest information, too.
- Meanwhile, while the online store is transacting, so is the storefront (Figure 5). It has a new purchase made by a new customer, Steve Smith, for a sweater. And that information also is shared in real-time with the shipping company they work with and no one else.
Figure 5: Simultaneous transactions in subsets of the partner ecosystem get real-time updates with control, too
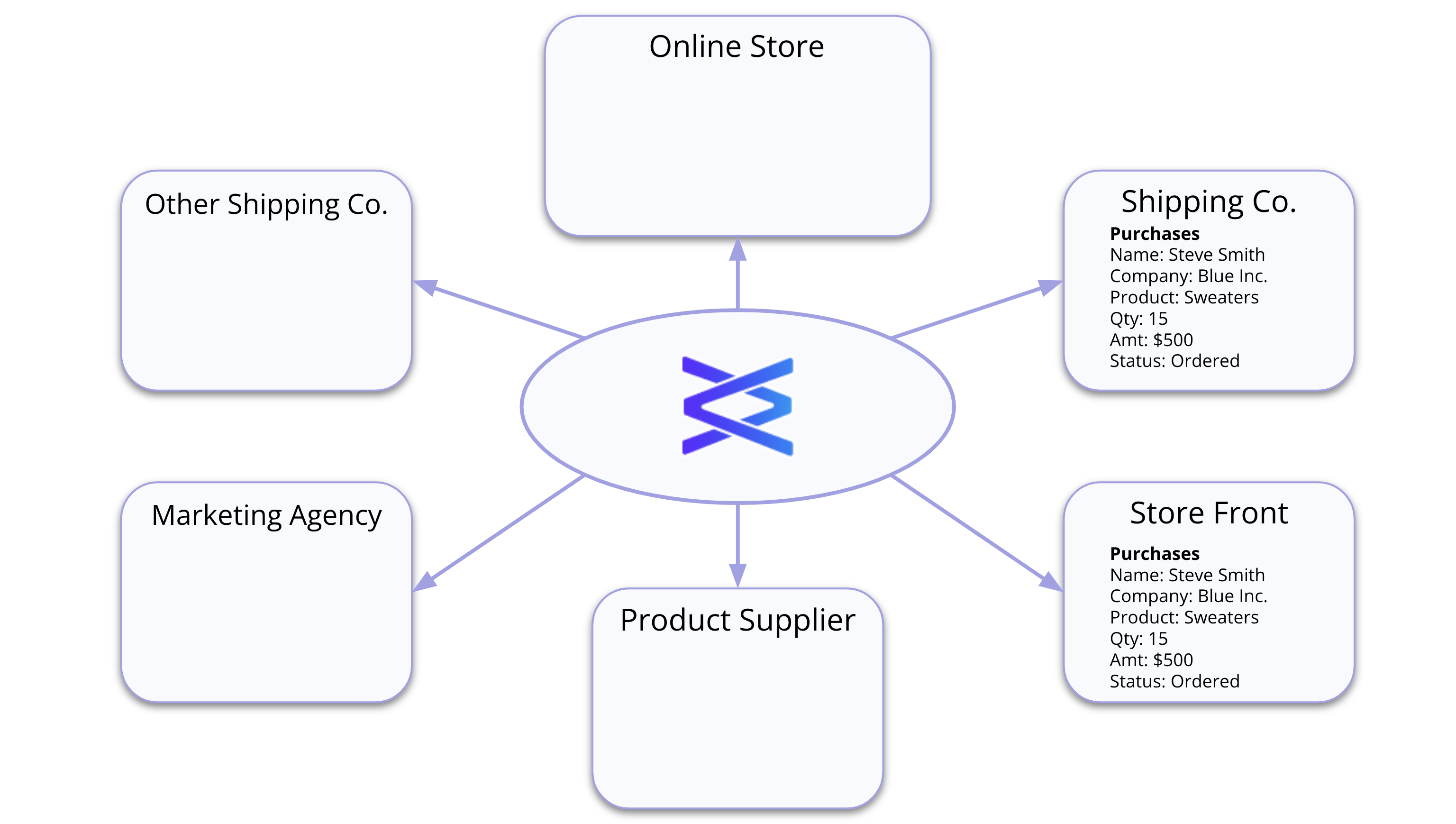
It’s real-time without integration, parallel shares, merging, and manual reconciliation of updates. It’s automated, trusted, compliant, and secure. And this is a great fit, not just for analytical data worlds but also for the operational data world using data that’s driving business processes.
How does Vendia Share know to redact intellectual property (IP), personally identifiable information (PII), or other sensitive information?
When you push data through Vendia Share, you can immediately apply rules that specify who can do what to that data. In semi-technical terms, you specify standard CRUD operations (read, write, delete, etc.), and you can specify it field by field, partner by partner, and so on. This gives you the power to collaborate with fine-grained control.
You don’t have to choose between data sharing and data collaboration
Data sharing and data collaboration are like cousins (or co-founders who work wonderfully together):
- Data sharing is great for expanding analytic insights when you consume new data that’s shared with you. It’s also great when you can maintain control of the state of data (when you’re the only source of truth) and consolidate data-driven workloads onto Snowflake for analytical purposes.
- Data in collaboration should be used for scenarios to create a multi-party, multi-directional solution in which a network produces and consumes respective updates.
For example, data collaboration is great for integrating data into your broader ecosystem via your CRM applications (I see you, Salesforce), inventory management tools, or financial systems. And it’s key to ensuring your version of the truth is accurate and timely since everyone is working on the same single version of the truth with real-time updates.
Use tools that are purpose-built for the job
To be clear, I’m not advocating for consolidating all data-related solutions onto a single tool. I’m advocating for the opposite. Use the tool purpose-fit for the job at hand, but make sure it plays nicely with others and appreciates a holistic data approach (Figure 6).
Figure 6: Use Vendia Share and Snowflake to treat data like a product
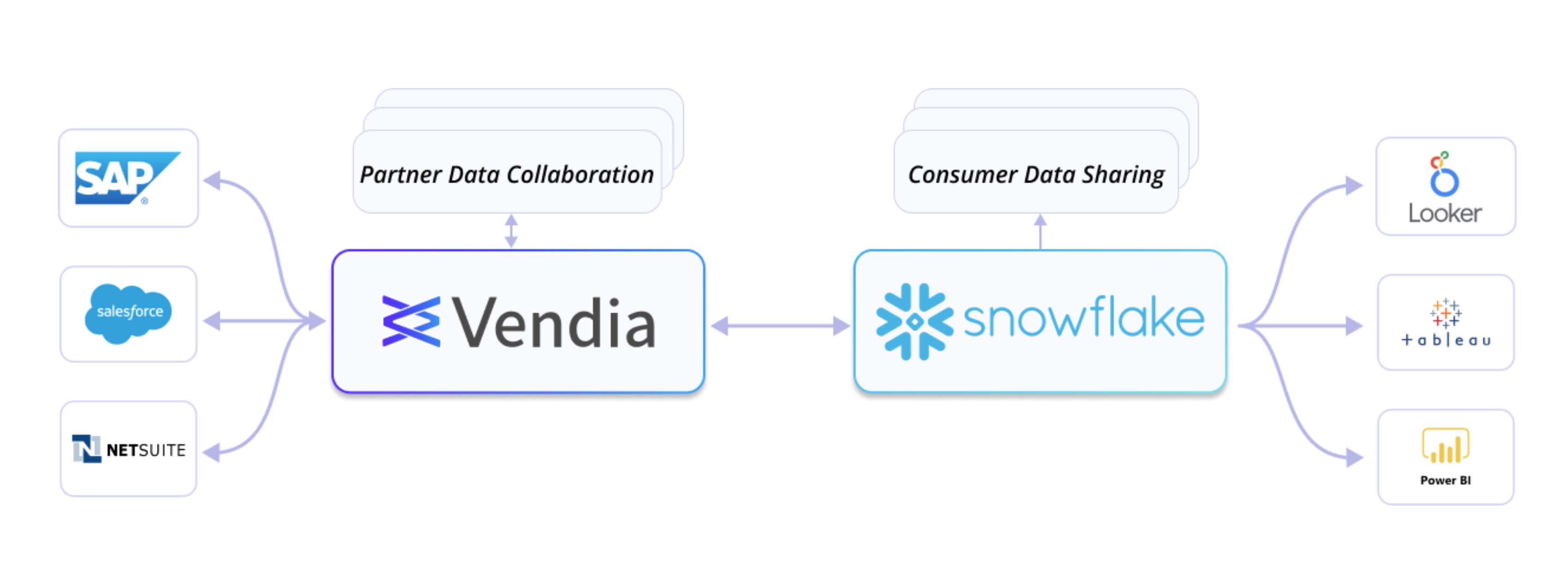
Using both Snowflake and Vendia Share combines purpose with power, unlocking opportunities from data outside of your four wallsIn a connected data ecosystem, you can holistically tackle your business initiatives, building answers to analytics and operational systems because you treat data like a product. You’re also reducing opportunity costs and the headcount needed for complex data integration, consolidation, and reconciliation. And this is really what the future of data of looks like.
How does data move in your company?
If you only move data in a one-way direction, you have what you need with Snowflake. But you need more if you are trying to go reconciliation-less and automate updates across your business network.
If you’re looking for ways to improve data collaboration with multiple partners inside and outside your four walls, contact us. We’ll walk through some of your use cases and help you understand if Vendia Share is right for your data landscape. If you want to see the platform in action, request a demo.